The year 2017 marked a seismic shift in Artificial Intelligence. Before then, teaching machines to understand language was like trying to read a book through a drinking straw—you could only see one word at a time, often forgetting the beginning of the sentence by the time you reached the end.
Then came the paper “Attention Is All You Need” by researchers at Google. It introduced the Transformer architecture, which threw away the drinking straw and allowed AI to read the entire page at once. This single architecture laid the foundation for the generative AI revolution we are living in today, from ChatGPT to Midjourney.
If you’ve ever wondered how these models actually “think,” TipTinker is here to break it down. We’re moving beyond the math to give you a clear, visual understanding of the engine driving modern AI.
The Core Concept: Why “Attention”?
To understand the Transformer, you have to understand the problem it solved. Previous models (like RNNs and LSTMs) processed data sequentially—step by step, word by word. This had two major flaws:
- It was slow: You couldn’t parallelize the training.
- It had amnesia: The model struggled to remember the context of a word if it appeared 50 words earlier.
The Transformer introduced a mechanism called Self-Attention. Instead of reading left-to-right, the model looks at every word in a sentence simultaneously and decides how much “attention” to pay to each one relative to the others.
The “Cocktail Party” Analogy
Imagine you are at a loud party.
- The Input: The combined noise of 100 people talking.
- The Mechanism: Your brain can filter out the noise and focus (attend) specifically on the person mentioning your name across the room, while ignoring the person shouting next to you.
- The Result: You extract relevant context regardless of “distance” or noise.
This is exactly what the Transformer does. It assigns a “relevance score” between every pair of words in a sequence.
The Engine Room: How Self-Attention Works
At a technical level, Self-Attention relies on three distinct vectors created for every word. Think of this as a database query system:
- Query (Q): What am I looking for? (e.g., “I am the word ‘Bank’, what is my context?”)
- Key (K): What can I offer? (e.g., “I am the word ‘River’, I offer geographical context.”)
- Value (V): What is my actual content? (e.g., The mathematical vector representation of the word ‘River’.)
The model calculates the dot product of the Query and Key to get a score (how relevant are these two words?). It then uses that score to weigh the Value.
Code Block: The Math of Attention
Here is the core formula from the paper, translated into Python-style pseudocode for clarity:
import numpy as np
def scaled_dot_product_attention(query, key, value):
"""
Computes the 'relevance' between words.
"""
# 1. Calculate the dot product (similarity score) between Query and Key
score = np.matmul(query, key.transpose())
# 2. Scale the score to keep gradients stable (divide by sqrt of dimension)
scaled_score = score / np.sqrt(query.shape[-1])
# 3. Apply Softmax to get probabilities (weights sum to 1.0)
attention_weights = softmax(scaled_score)
# 4. Multiply weights by Value to get the final context-aware vector
output = np.matmul(attention_weights, value)
return output, attention_weights
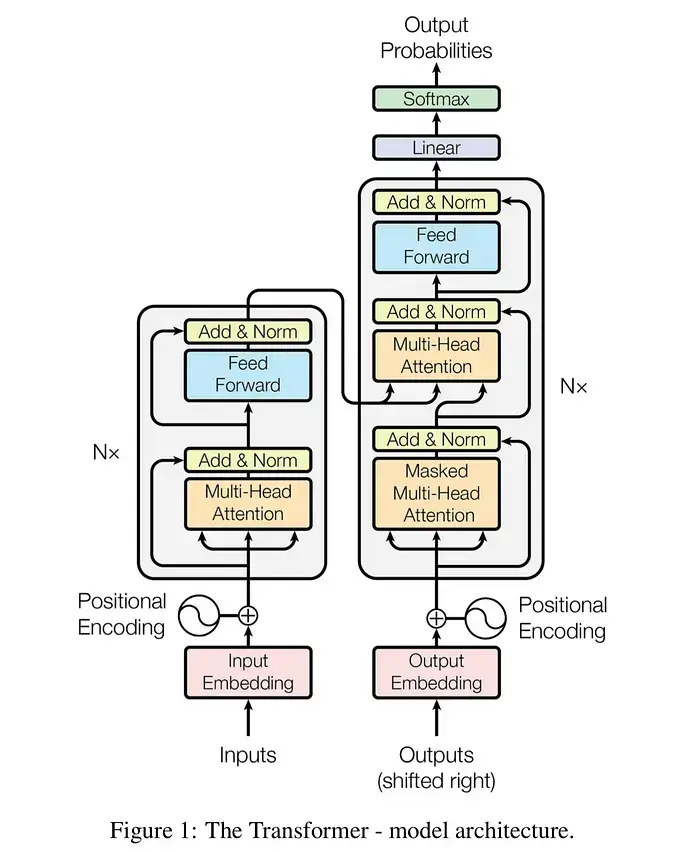
Visualizing the Architecture
The Transformer is split into two main stacks: the Encoder (which processes input) and the Decoder (which generates output).
Visual Aid: The Transformer Stack
Imagine a factory assembly line.
graph TD
A[Input Sentence] --> B[Embeddings + Positional Encoding]
B --> C{Encoder Block}
C -->|Self-Attention| D[Analyze Context]
D -->|Feed Forward| E[Process Features]
E --> F{Decoder Block}
F -->|Masked Attention| G[Look at previous outputs]
F -->|Cross-Attention| H[Look at Encoder Output]
H --> I[Output Probabilities]
I --> J[Next Word Generated]
- Positional Encoding: Since the model looks at all words at once, it needs to know the order. We inject a “timestamp” signature into each word’s data so the model knows “Dog bites Man” is different from “Man bites Dog.”
- Multi-Head Attention: Instead of one focus point, the model uses multiple “heads.” One head might focus on grammar, another on vocabulary, and another on emotional tone.
- Feed-Forward Networks: Simple neural networks that process the information after attention has been applied.
Step-by-Step Guide: The Information Flow
Here is how a Transformer processes the sentence “The animal didn’t cross the street because it was too tired.” to understand what “it” refers to.
Step 1: Tokenization & Embedding
- Action: The sentence is broken into tokens (numbers).
- Result: Each word converts into a dense vector (a list of coordinates representing its meaning).
Step 2: Positional Encoding
- Action: The model adds a sine-wave signal to the vectors.
- Result: The word “street” now carries information that it appears after “cross” and before “because.”
Step 3: Multi-Head Attention (The Magic Step)
- Action: The model asks, “What does ‘it’ relate to?”
- Head 1 (Grammar): Links “it” to “animal” (Subject-Noun agreement).
- Head 2 (Context): Links “tired” to “animal” (Animals get tired; streets do not).
- Result: The representation of “it” is updated to include the essence of “animal.”
Step 4: Feed-Forward & Normalization
- Action: The data passes through standard neural layers to digest the new context.
- Result: The vectors are refined and prepared for the next layer or output.
Step 5: Decoding (Generation)
- Action: If translating to French, the Decoder looks at the Encoder’s rich representation of “animal” and “tired” to produce the correct gendered pronoun in French (il or elle).
🚀 Pro-Tips: Transformers in Practice
If you are working with or fine-tuning Transformer models, keep these distinctions in mind.
| Feature | RNNs / LSTMs (Old School) | Transformers (New School) |
|---|---|---|
| Processing | Sequential (Slow) | Parallel (Fast) |
| Context Window | Short (Forgets early words) | Long (Remembers entire prompt) |
| Best Use Case | Simple Time-Series data | NLP, Vision, Biology (Protein Folding) |
| Training Cost | Lower compute, longer time | High compute, shorter time |
Best Practices:
- Context Window Matters: When using LLMs (like GPT-4), the “context window” is essentially how much “Attention” memory the model has. If you exceed it, the model “forgets” the start of the conversation.
- Pre-training vs. Fine-tuning: You rarely need to build a Transformer from scratch. The power lies in taking a pre-trained model (that already understands language structure) and fine-tuning it on your specific data (legal docs, medical records, etc.).
The “Attention Is All You Need” paper didn’t just improve translation; it redefined how computers process information. By allowing models to parallelize processing and weigh the relationship of every data point to every other data point dynamically, we achieved the level of “understanding” we see in AI today.
Whether you are a developer looking to fine-tune BERT or a user trying to write better prompts, remember: it’s all about context. The better the context you provide, the effectively the Attention mechanism can route that information to the right place.
Go ahead and look at your next AI prompt differently—you now know the engine running underneath the hood.
📚 Further Reading & Resources
- The Original Paper: Attention Is All You Need (ArXiv)
- The Illustrated Transformer by Jay Alammar (A legendary visual guide)
- Annotated Transformer (Harvard NLP) (PyTorch implementation)