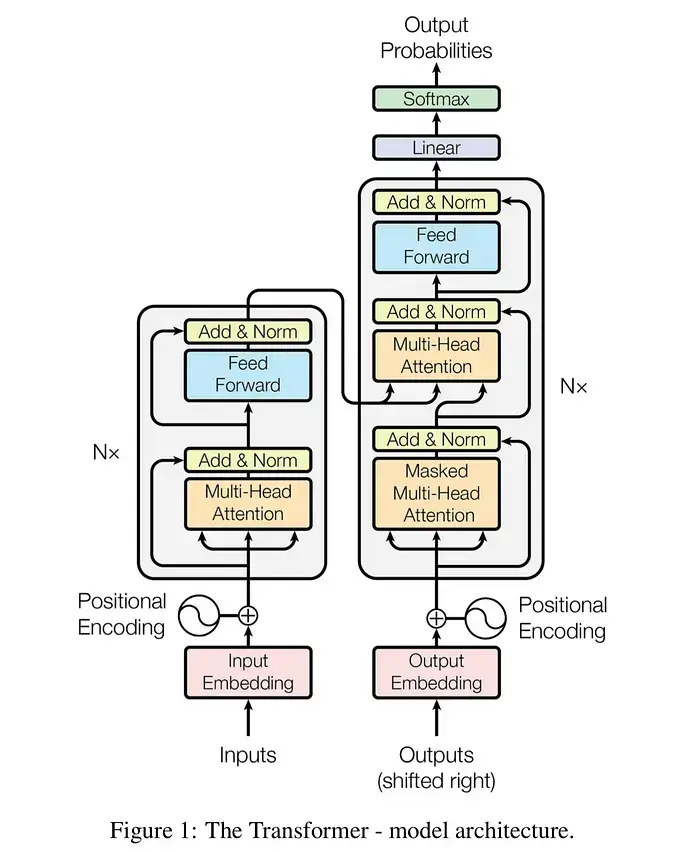
2017年、Google Brainの研究者たちが発表した論文「Attention Is All You Need」は、AIの歴史における転換点となりました。現在のChatGPT、Claude、DeepLなどの基盤となっている技術、Transformerはこの論文から生まれました。
従来のRNN(リカレントニューラルネットワーク)やLSTMが抱えていた「並列処理ができない」「長距離の文脈を保持できない」という致命的なボトルネックを、Transformerはいかにして解消したのか? 本記事では、その核心である「Attentionメカニズム」とアーキテクチャの構造を視覚的かつ技術的に解説します。
Transformerが革命的である理由
Transformer以前の自然言語処理は、単語を先頭から順番に処理する必要がありました。しかし、Transformerは**「Attention(注意機構)」を用いることで、文中のすべての単語の関係性を同時に(並列に)**計算することを可能にしました。
核心概念は以下の3点に集約されます:
- 並列処理(Parallelism): 全データを一度に処理できるため、学習速度が飛躍的に向上。
- 自己注意機構(Self-Attention): 文中のある単語が、他のどの単語と強く関連しているかを数値化。
- 位置エンコーディング(Positional Encoding): 順序情報を持たない構造に対し、単語の位置情報を数学的に付与。
【アーキテクチャ図解】データの流れ
Transformerの構造は複雑に見えますが、大きく「エンコーダー(情報の圧縮)」と「デコーダー(情報の生成)」に分かれます。以下は、そのデータフローを可視化したものです。
graph TD
subgraph "Encoder Stack (入力処理)"
A["入力テキスト (Input Text)"] --> B["埋め込み層 (Input Embedding)"]
B --> C["位置エンコーディング (Positional Encoding)"]
C --> D["マルチヘッド・アテンション (Multi-Head Attention)"]
D --> E["残差接続 & 正規化 (Add & Norm)"]
E --> F["フィードフォワード層 (Feed Forward)"]
F --> G["残差接続 & 正規化 (Add & Norm)"]
end
subgraph "Decoder Stack (出力生成)"
H["出力 (Outputs / Shifted Right)"] --> I["埋め込み層 (Output Embedding)"]
I --> J["位置エンコーディング (Positional Encoding)"]
J --> K["マスク付きアテンション (Masked Multi-Head Attention)"]
K --> L["残差接続 & 正規化 (Add & Norm)"]
G --> M["エンコーダー・デコーダーアテンション (Cross Attention)"]
L --> M
M --> N["残差接続 & 正規化 (Add & Norm)"]
N --> O["フィードフォワード層 (Feed Forward)"]
O --> P["残差接続 & 正規化 (Add & Norm)"]
end
P --> Q["線形層 (Linear)"]
Q --> R["ソフトマックス (Softmax)"]
R --> S["最終出力確率 (Output Probabilities)"]
style A fill:#f9f,stroke:#333,stroke-width:2px
style S fill:#9ff,stroke:#333,stroke-width:2px
style D fill:#ff9,stroke:#333,stroke-width:2px
style M fill:#ff9,stroke:#333,stroke-width:2px
核心コード:Scaled Dot-Product Attention
Transformerの心臓部は、Query (Q)、Key (K)、Value (V) という3つのベクトルを用いた行列計算です。これはデータベースの検索に似ています(クエリを投げ、キーと照合し、値を取り出す)。
以下は、論文の数式 をPyTorchで実装したものです。
import torch
import torch.nn.functional as F
import math
def scaled_dot_product_attention(query, key, value, mask=None):
"""
Scaled Dot-Product Attentionの実装
Args:
query: 検索クエリ (Batch, Heads, Seq_Len_Q, Depth)
key: 照合キー (Batch, Heads, Seq_Len_K, Depth)
value: 抽出する値 (Batch, Heads, Seq_Len_K, Depth)
mask: 特定の単語を無視するためのマスク (オプション)
"""
d_k = query.size(-1) # 次元のサイズ
# 1. QとKの転置の内積を計算(関連度スコア)
scores = torch.matmul(query, key.transpose(-2, -1))
# 2. 次元のルートで割ってスケーリング(勾配消失防止)
scores = scores / math.sqrt(d_k)
# 3. マスク適用(必要な場合、未来の単語などを隠す)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 4. Softmaxで確率分布(重み)に変換
attention_weights = F.softmax(scores, dim=-1)
# 5. 重みに基づいてValueを加重平均
output = torch.matmul(attention_weights, value)
return output, attention_weights
ステップバイステップ:処理の仕組み
Transformerが「I love AI」という文を翻訳・理解する際、内部では以下の処理が行われています。
- トークン化と埋め込み (Embedding)
- テキストを数値IDに変換し、それを密なベクトル(例:512次元の数値列)に変換します。この時点で「King」と「Queen」のような意味の近い単語は、数学的に近い距離に配置されます。
- 位置情報の付与 (Positional Encoding)
- Transformerは同時並行処理を行うため、「順序」の概念がありません。そこで、サイン波・コサイン波を用いた数値をベクトルに加算し、「これは1番目の単語」「これは2番目の単語」という情報を埋め込みます。
- 自己注意 (Self-Attention)
- ここが最重要です。「it」という単語がある場合、それが前の文の「animal」を指すのか「street」を指すのかを、周囲の単語との関連度(スコア)計算によって特定します。
- フィードフォワードと正規化
- 抽出された特徴量をさらに加工し、次の層へ渡します。残差接続(Residual Connection)により、深い層でも学習が安定します。
- デコーディングと出力
- エンコーダーが作った文脈情報を受け取り、デコーダーが1単語ずつ(自己回帰的に)確率の高い次の単語を予測・生成します。
比較:RNN vs Transformer
なぜ世界はRNN/LSTMを捨ててTransformerに移行したのでしょうか?
| 特徴 | RNN / LSTM (従来) | Transformer (現在) |
|---|---|---|
| 処理方法 | シーケンシャル(直列・1単語ずつ) | パラレル(並列・全単語同時) |
| 計算速度 | 遅い(GPUの並列性能を活かせない) | 極めて高速 |
| 長距離依存 | 苦手(文が長くなると文脈を忘れる) | 得意(どれだけ離れていても参照可能) |
| 学習データ量 | 限定的 | Web全体規模のデータで学習可能 |
| 主な用途 | 以前の翻訳、時系列データ | LLM (GPT-4), BERT, 画像生成 |
Pro-Tips: 実装と活用のポイント
Transformerモデルを扱う、あるいは理解を深めるための実践的なヒントです。
- コンテキストウィンドウの理解:
Transformerにおける「入力トークン数制限(例:GPT-4の128k)」は、Attention行列のメモリ使用量がシーケンス長の二乗()で増加することに起因します。長いプロンプトを投げる際は、この計算コストが背後にあることを意識してください。 - ファインチューニングの効率化:
フルスクラッチでTransformerを学習させるには莫大なリソースが必要です。実務では、事前学習済みモデル(BERTやLlamaなど)に対し、LoRA (Low-Rank Adaptation) などの技術を使って、Attention層の一部の重みだけを調整するのが一般的です。 - Temperatureの設定:
最後のSoftmax層にかかる温度パラメータ(Temperature)は、確率分布の「平坦さ」を調整します。創造性が必要な場合は数値を上げ(分布を平坦にし、レアな単語も選ばれやすくする)、正確性が必要な場合は下げます。
「Attention Is All You Need」は、単なる論文のタイトルではなく、現代AIの基本原理そのものを表しています。複雑な再帰処理(Recurrence)や畳み込み(Convolution)を捨て、「注目(Attention)」のみにリソースを集中させたこのアーキテクチャが、今の生成AIブームを支えています。
次にChatGPTを使うときは、あなたの入力した全単語に対して、瞬時に数億回の行列計算(Attention)が行われていることを想像してみてください。