ChatGPT、Claude、Gemini——这些改变世界的 AI 模型背后,都站着同一个巨人:2017 年 Google 团队发表的论文 《Attention Is All You Need》。
在这篇文章发表之前,自然语言处理(NLP)是循环神经网络(RNN)和 LSTM 的天下。然而,这些旧架构像是一条单行道,处理长文本时效率低下且容易“遗忘”。Transformer 的出现,彻底打破了顺序处理的枷锁,开启了并行计算的 AI 黄金时代。
本文将剥离复杂的数学公式,通过可视化图解和核心代码,带你彻底看懂 Transformer 的内部构造。
核心概念:为什么是 Transformer?
在 Transformer 出现之前,NLP 模型处理句子像是在读一本书:必须读完上一页,才能读下一页(顺序处理)。如果你读到第 100 页时忘了第 1 页的内容,模型就崩塌了。
Transformer 做出的最大改变是并行化(Parallelization)。它能像拥有“上帝视角”一样,同时看到句子中的每一个词,并瞬间计算出词与词之间的关联强度。这种机制的核心,就是 自注意力机制(Self-Attention)。
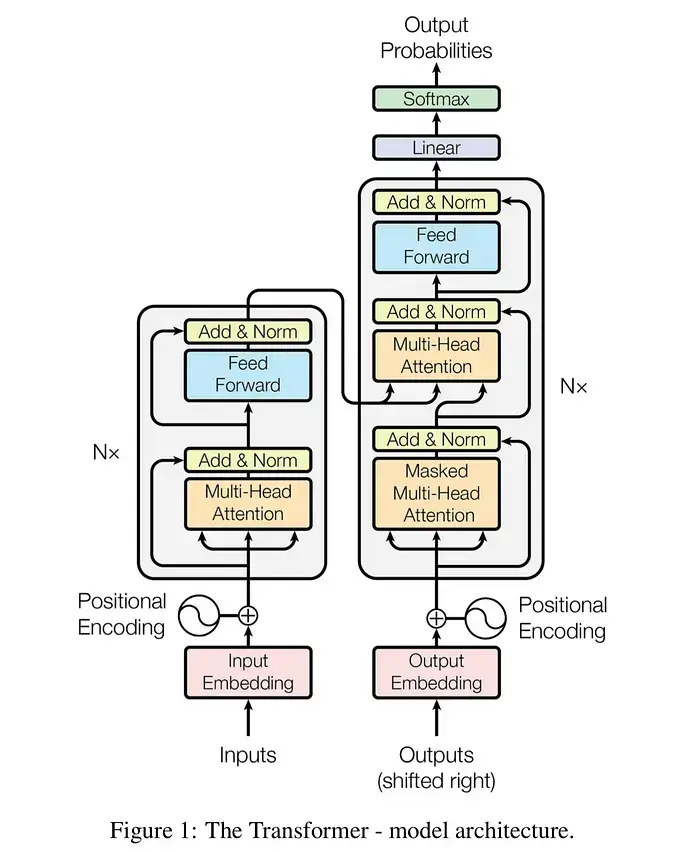
Transformer 宏观架构图
graph TD
subgraph "Encoder (编码器)"
A["输入 (Inputs)"] --> B["输入嵌入 (Input Embeddings)"]
B --> C["位置编码 (Positional Encoding)"]
C --> D["多头注意力 (Multi-Head Attention)"]
D --> E["层归一化 (Add & Norm)"]
E --> F["前馈神经网络 (Feed Forward)"]
F --> G["层归一化 (Add & Norm)"]
end
subgraph "Decoder (解码器)"
H["输出 (Outputs)"] --> I["输出嵌入 (Output Embeddings)"]
I --> J["位置编码 (Positional Encoding)"]
J --> K["掩码多头注意力 (Masked Multi-Head Attention)"]
K --> L["层归一化 (Add & Norm)"]
L --> M["多头注意力 (Multi-Head Attention)"]
M --> N["层归一化 (Add & Norm)"]
N --> O["前馈神经网络 (Feed Forward)"]
O --> P["层归一化 (Add & Norm)"]
end
G --> M
P --> Q["线性层 & Softmax (Linear & Softmax)"]
Q --> R["最终输出概率 (Output Probabilities)"]
上面的流程图展示了 Transformer 的经典 Encoder-Decoder(编码器-解码器)结构。
核心组件解析:Q, K, V 的秘密
Transformer 中最抽象也最重要的概念是 Query (查询)、Key (键) 和 Value (值)。
想象你在图书馆找资料:
- Query (Q):你手中的书单(你想找什么)。
- Key (K):书脊上的标签(书的分类信息)。
- Value (V):书里的实际内容(你真正需要的知识)。
注意力机制就是计算 Query 和 Key 的匹配度(相似性)。匹配度越高,你对这本书的 Value 投入的注意力就越多。
数学公式(可视化理解)
注意力分数的计算公式如下:
- :计算查询与所有键的相似度(点积)。
- :缩放因子,防止梯度消失。
- Softmax:将分数归一化为概率(所有分数加起来等于 1)。
- :根据概率加权求和,提取重要信息。
核心代码实现 (PyTorch)
不要被理论吓倒,用 Python 实现核心的“缩放点积注意力”其实非常简洁:
import torch
import torch.nn.functional as F
import math
def scaled_dot_product_attention(query, key, value, mask=None):
"""
计算注意力机制的核心函数
query, key, value 的维度: (batch_size, num_heads, seq_len, depth)
"""
d_k = query.size(-1)
# 1. 计算 Q 和 K 的点积 (QK^T)
scores = torch.matmul(query, key.transpose(-2, -1))
# 2. 缩放 (Scale)
scores = scores / math.sqrt(d_k)
# 3. 应用掩码 (Masking) - 用于解码器,防止看到未来的词
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 4. Softmax 归一化
attention_weights = F.softmax(scores, dim=-1)
# 5. 与 V 相乘得到最终输出
output = torch.matmul(attention_weights, value)
return output, attention_weights
关键机制分步拆解
1. 多头注意力 (Multi-Head Attention)
如果只用一组 Q、K、V,可能只能捕捉到一种语义关系(例如语法关系)。
多头注意力 就像是让 8 个不同视角的专家同时读一句话:
- 专家 A 关注语法结构。
- 专家 B 关注指代关系(例如 “它” 指的是谁)。
- 专家 C 关注情感色彩。
最后将这 8 个专家的结果拼接起来,通过一个线性层融合。
2. 位置编码 (Positional Encoding)
因为 Transformer 是并行处理所有词的,它本身不知道 “我爱你” 和 “你爱我” 中词序的区别。
位置编码 是给每个词的向量加上一个独特的“位置指纹”(基于正弦和余弦函数),让模型知道词在句子中的先后顺序。
3. 残差连接与归一化 (Add & Norm)
- 残差连接 (Residual Connection):将输入直接加到输出上 (),就像给信息修了一条高速公路,防止深层网络中信息丢失。
- 层归一化 (Layer Normalization):稳定训练过程,加速收敛。
深度对比:RNN vs Transformer
为了更直观地理解 Transformer 的优势,我们来看一组对比数据:
| 特性 | RNN / LSTM (旧时代) | Transformer (新时代) |
|---|---|---|
| 计算方式 | 串行 (Sequential) | 并行 (Parallel) |
| 长距离依赖 | 弱 (距离越远越容易遗忘) | 强 (任意两个词距离为 1) |
| 训练速度 | 慢 (无法充分利用 GPU) | 快 (极度适合 GPU 并行) |
| 上下文理解 | 单向或伪双向 | 真正的双向 (Bidirectional) |
| 典型代表 | Seq2Seq, Google Translate (Old) | BERT, GPT-4, Llama |
专家建议 (Pro-Tips)
如果你正在学习或尝试复现 Transformer,请注意以下几点:
- Warmup 策略至关重要:Transformer 对学习率非常敏感。训练初期需要使用
Warmup策略,即先线性增加学习率,再按平方根倒数衰减,否则模型很难收敛。 - 掩码 (Masking) 别搞错:在 Decoder 训练时,必须使用
Look-ahead Mask(前瞻掩码),确保预测第 个词时,只能看到 之前的信息,绝对不能“偷看”答案。 - Embedding 维度:原始论文中 ,但在实际微调小任务时,降低维度(如 256 或 128)往往能防止过拟合且速度更快。
总结与行动
《Attention Is All You Need》不仅仅是一篇论文,它是现代生成式 AI 的基石。它告诉我们:只要有足够的计算资源和数据,注意力机制 足以捕捉人类语言的复杂规律。
下一步行动:
不要止步于理论。打开你的 Python 编辑器(或 Colab),尝试调用 torch.nn.Transformer 模块,跑通一个简单的机器翻译 Demo。只有亲手看到 Loss 下降,你才算真正理解了它。
参考资料
- Vaswani et al., “Attention Is All You Need”, NeurIPS 2017
- The Illustrated Transformer by Jay Alammar
- PyTorch Documentation: Transformer Layers