우리가 사용하는 ChatGPT, Claude, Gemini와 같은 모든 최신 AI 모델의 심장부에는 **’트랜스포머(Transformer)’**라는 아키텍처가 있습니다. 2017년 구글이 발표한 논문 *”Attention Is All You Need”*는 인공지능의 역사를 새로 썼지만, 수식으로 가득 찬 논문을 이해하기란 쉽지 않습니다.
이 글에서는 복잡한 수학 대신 직관적인 비유와 시각적 구조를 통해 트랜스포머가 어떻게 문맥을 이해하고 언어를 생성하는지 명확하게 파헤칩니다.
1. 핵심 개념: 왜 트랜스포머인가? (RNN vs Transformer)
과거의 언어 모델(RNN, LSTM)은 문장을 읽을 때 인간처럼 왼쪽에서 오른쪽으로 한 단어씩 순서대로 처리했습니다. 이 방식은 문장이 길어질수록 앞부분의 내용을 잊어버리는 치명적인 단점이 있었습니다.
트랜스포머는 **’병렬 처리(Parallel Processing)’**와 **’어텐션(Attention)’**이라는 두 가지 무기로 이 문제를 해결했습니다.
- 병렬 처리: 문장 전체를 한 번에 입력받아 모든 단어를 동시에 분석합니다.
- 어텐션(Attention): 문장 내의 단어들이 서로 어떤 관계가 있는지(어디에 주목해야 하는지) 계산합니다.
💡 비유: 도서관 사서
- RNN: 사서가 책의 첫 페이지부터 끝까지 한 줄씩 읽으며 내용을 기억하려고 애씁니다. 책이 두꺼우면 앞 내용을 잊어버립니다.
- Transformer: 사서가 책의 모든 페이지를 바닥에 펼쳐놓고, 관련된 내용끼리 형광펜으로 연결하며 전체 맥락을 한눈에 파악합니다.
2. 코드 블록: 어텐션 메커니즘의 수학적 구현 (Python)
트랜스포머의 핵심인 ‘Scaled Dot-Product Attention’을 파이썬 코드로 구현하면 그 원리가 더 명확해집니다.
import numpy as np
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(query, key, value, mask=None):
"""
Query, Key, Value 행렬을 사용한 어텐션 스코어 계산
"""
d_k = query.size(-1) # 차원 크기
# 1. 어텐션 스코어 계산 (Query와 Key의 내적)
scores = torch.matmul(query, key.transpose(-2, -1)) / np.sqrt(d_k)
# 2. 마스킹 (옵션: 디코더에서 미래 단어 참조 방지 등)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 3. Softmax 적용 (확률 분포로 변환)
attention_weights = F.softmax(scores, dim=-1)
# 4. Value와 가중합 (최종 문맥 벡터 생성)
output = torch.matmul(attention_weights, value)
return output, attention_weights
3. 단계별 가이드: 트랜스포머 내부 동작 원리
트랜스포머가 “The bank of the river”라는 문장을 처리하는 과정을 5단계로 시각화해 보겠습니다.
- 임베딩 & 포지셔널 인코딩 (Input Embedding & Positional Encoding)
- 동작: 단어를 숫자로 된 벡터로 변환합니다. 동시에 단어의 위치 정보(순서)를 더해줍니다.
- 이유: 트랜스포머는 단어를 동시에 처리하므로, 단어의 순서를 알려주는 좌표값이 필요합니다.
- 셀프 어텐션 (Self-Attention): 문맥 파악의 핵심
- 동작: 각 단어가 문장 내 다른 모든 단어와 얼마나 연관되어 있는지 계산합니다.
- Q, K, V 개념:
- Query (질문): “나(현재 단어)와 관련된 정보가 있나요?”
- Key (색인): “저는 이런 내용을 담고 있습니다.”
- Value (내용): “제 실제 데이터는 이것입니다.”
- 예시: “bank”라는 단어가 있을 때, 주변의 “river”라는 단어에 높은 점수(Attention Score)를 주어 “은행”이 아닌 “강둑”임을 파악합니다.
- 멀티 헤드 어텐션 (Multi-Head Attention)
- 동작: 셀프 어텐션을 여러 개(예: 8개) 복제하여 동시에 수행합니다.
- 이유: 하나의 관점만으로는 부족합니다. 어떤 헤드는 ‘문법’을 보고, 어떤 헤드는 ‘의미’를 보고, 어떤 헤드는 ‘대명사 관계’를 봅니다.
- 피드 포워드 네트워크 (Feed-Forward Networks)
- 동작: 어텐션으로 모인 정보를 각 단어별로 독립적으로 가공하여 더 깊은 특징을 추출합니다.
- 인코더-디코더 연결 (Encoder-Decoder Attention)
- 동작: (번역 등의 작업 시) 인코더가 분석한 원문 정보를 디코더에 전달합니다. 디코더는 생성할 단어를 결정할 때 원문의 어느 부분을 참고할지 결정합니다.
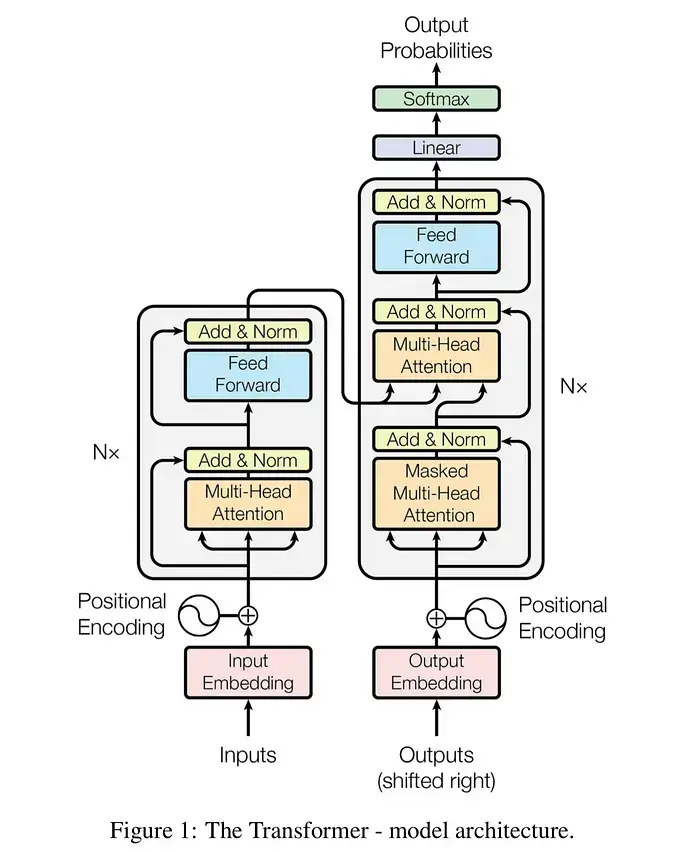
4. 비주얼 데이터: 트랜스포머 구조 다이어그램
아래 다이어그램은 트랜스포머의 전체적인 데이터 흐름을 보여줍니다.
graph TD
Input["입력 문장 (Inputs)"] --> Emb["임베딩 + 위치 인코딩"]
Emb --> EncBlock["인코더 블록 (Encoder Block)"]
subgraph Encoder_Layer ["인코더 레이어 (반복)"]
direction TB
MultiHead1["멀티 헤드 어텐션 (Self-Attention)"]
AddNorm1["Add & Norm"]
FFN1["Feed Forward"]
AddNorm2["Add & Norm"]
MultiHead1 --> AddNorm1
AddNorm1 --> FFN1
FFN1 --> AddNorm2
end
EncBlock --> Encoder_Layer
subgraph Decoder_Layer ["디코더 레이어 (반복)"]
direction TB
MaskedAtt["마스크드 멀티 헤드 어텐션"]
AddNorm3["Add & Norm"]
EncDecAtt["멀티 헤드 어텐션 (Encoder-Decoder)"]
AddNorm4["Add & Norm"]
FFN2["Feed Forward"]
AddNorm5["Add & Norm"]
MaskedAtt --> AddNorm3
AddNorm3 --> EncDecAtt
EncDecAtt --> AddNorm4
AddNorm4 --> FFN2
FFN2 --> AddNorm5
end
Encoder_Layer -- "K, V 행렬 전달" --> EncDecAtt
OutputShifted["출력 문장 (Shifted Right)"] --> EmbDec["임베딩 + 위치 인코딩"]
EmbDec --> Decoder_Layer
Decoder_Layer --> Linear["Linear & Softmax"]
Linear --> FinalProb["다음 단어 확률"]
트랜스포머 주요 구성 요소 비교
| 구성 요소 | 역할 | 비유 (Analogy) |
|---|---|---|
| Self-Attention | 문장 내 단어 간 관계 파악 | 파티에서 내 이름이 들릴 때 그쪽으로 귀를 기울이는 것 |
| Multi-Head Attention | 다양한 관점에서 문맥 이해 | 여러 명의 전문가가 문장을 문법, 의미, 화자 등 각기 다른 관점으로 분석 |
| Positional Encoding | 단어의 순서 정보 주입 | 섞여 있는 퍼즐 조각 뒤에 적힌 번호표 |
| Residual Connection | 학습 정보 손실 방지 | 정보를 잊지 않도록 원본 데이터를 그대로 다음 단계로 넘겨주는 지름길 |
5. 전문가 팁 (Pro-Tips)
- 배치 크기(Batch Size)가 중요하다: 트랜스포머는 병렬 처리에 최적화되어 있습니다. 학습 시 GPU 메모리가 허용하는 한 배치 크기를 키우면 학습 속도가 비약적으로 상승합니다.
- 사전 학습(Pre-training) 활용: 처음부터 모델을 학습시키는 것은 비효율적입니다. Hugging Face 등에서 BERT나 GPT 계열의 사전 학습된 모델을 가져와 파인튜닝(Fine-tuning)하는 것이 성능 확보의 지름길입니다.
- Warm-up Steps: 학습 초기에는 학습률(Learning Rate)을 매우 낮게 시작하여 점차 올리는 ‘Warm-up’ 전략을 사용해야 모델이 초기에 불안정하게 발산하는 것을 막을 수 있습니다.
6. 결론 및 요약
“Attention Is All You Need”는 단순한 논문 제목을 넘어 현대 AI의 철학이 되었습니다. 순차적인 처리 방식을 버리고 **’관계(Attention)’**에 집중함으로써, 기계는 비로소 문맥을 깊이 있게 이해하게 되었습니다.
오늘 소개한 Query, Key, Value 개념과 멀티 헤드 구조만 기억한다면, 앞으로 나올 최신 LLM 논문들도 훨씬 쉽게 이해할 수 있을 것입니다. 지금 바로 PyTorch나 TensorFlow 공식 튜토리얼을 통해 간단한 트랜스포머 모델을 직접 코딩해 보시기를 권장합니다.
7. 참고 자료 (References)
- Attention Is All You Need (Original Paper)
- The Illustrated Transformer by Jay Alammar
- PyTorch Transformer Tutorial