2月5日、AIの風景は再び塗り替えられた。Claude 4.6 OpusとGPT-5.3 Codexが同時にリリースされ、両モデルは100万トークンという巨大なコンテキストウィンドウと「エージェント的推論」能力を謳っている。GoogleのGemini 3.0 Proと合わせて、役員会議室では2024年に聞いたあの危険な物語が再び囁かれている:「RAGは死んだ。データベース全体をプロンプトに放り込めばいい」
騙されてはいけない。
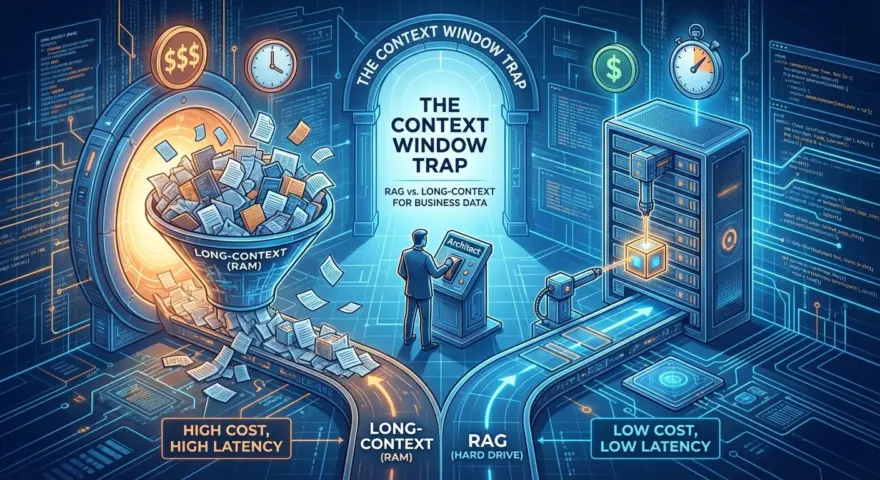
コンテキストウィンドウの罠とは、Gemini 3.0が2,000ページのコンプライアンスマニュアルを取り込めるからといって、取り込むべきだという誤った信念である。これらの最先端モデルがメガバイト規模の入力を当たり前にした一方で、企業データの検索にそれらだけを頼ることは、運用コストの破綻とレイテンシ地獄への一直線だ。
エンタープライズアーキテクトにとって、RAG(検索拡張生成)と長文コンテキスト推論の選択は最適化問題である。RAGはハードディスク(安価、大容量、静的)。長文コンテキストはRAM(高価、揮発性、高速)だ。
このガイドでは、2026年2月時点のモデルスタックの単価経済を分析し、この罠を生き延びるためのハイブリッド設計図を提供する。
規模の経済学:「怠惰な」アーキテクチャが失敗する理由
長文コンテキストの魅力はシンプルさだ。ベクトルデータベースやチャンキングパイプラインを取り除き、ただデータを貼り付ける。
しかし、今週発表された新価格表に基づくと、その夢を打ち砕く計算がある。
1. 「コンテキスト階層」ペナルティ(Gemini 3.0 Pro)
GoogleのGemini 3.0 Proの価格戦略は「コンテキスト税」を導入している。
- 標準コンテキスト(<20万トークン): 入力100万トークンあたり2.00ドル。
- 長文コンテキスト(>20万トークン): 入力100万トークンあたり4.00ドル。
もし30万トークンのマニュアルを怠惰にコンテキストに放り込めば、入力コストは即座に2倍になる。1日1万件の問い合わせを処理するカスタマーサポートエージェントにとって、この「怠惰税」は年間数百万ドルに積み上がる。
2. 「Opusクラス」推論の高コスト(Claude 4.6)
Claude 4.6 Opusは推論の傑作だが、入力100万トークンあたり5.00ドルかかる。
もしすべてのクエリに対して50ページの文書(約2.5万トークン)を入力すると:
- クエリあたりのコスト: 前置きを読むだけで約0.12ドル。
- RAGの代替案: 関連する1,000トークンのみを検索 → コスト:約0.005ドル。
- 結果: RAGはインタラクションあたり24倍安い。
3. レイテンシと「真ん中で迷子」現象
GPT-5.3 Codexが前身より25%高速化したと報告されていても、100万トークンの処理には数秒かかる。RAG検索はミリ秒単位だ。SLAがサブ秒応答を要求するなら、長文コンテキストは物理的に太刀打ちできない。さらに、改善はあるものの、コンテキストが無関係なノイズ(エントロピー)で飽和すると、「干し草の山の針探し」性能は依然として低下する。
設計図:10の精鋭プロンプト/設定
この罠を乗り切るには、ハイブリッドアーキテクチャが必要だ。以下のプロンプトと設定はルーティングロジックとして機能し、システムがRAGと長文コンテキストを動的に切り替えられるようにする。
1. 「交通整理係」ルーター(意思決定ノード)
これは最も重要なコンポーネント。ユーザークエリを分析し、全文書スキャン(長文コンテキスト)が必要か、特定の事実検索(RAG)が必要かを判断する。
ROLE: クエリ最適化エージェント。
TASK: ユーザークエリを分類し、検索戦略を決定する。
戦略:
1. 「特定検索」(RAG): 特定の事実、数字、日付、または単一エンティティの詳細を尋ねるクエリ用。(Gemini 3.0 Flashまたはインデックスにルーティング)。
2. 「全体分析」(長文コンテキスト): 要約、テーマ、全文書にわたる比較、または全文脈を必要とする「ハウツー」ガイドを尋ねるクエリ用。(Claude 4.6 Opusにルーティング)。
入力: {user_query}
出力 JSON:
{
"strategy": "SPECIFIC_RETRIEVAL" | "GLOBAL_ANALYSIS",
"reasoning": "クエリは特定の請求書番号を尋ねており、これは針探し型の検索である。"
}
2. コンテキスト圧縮設定(Claude 4.6スタイル)
Claude 4.6 Opusは「コンテキスト圧縮」APIを導入した。これを利用して、生ログを再読込するコストをかけずに、会話履歴を自動的に要約する。
# Anthropic圧縮APIの疑似コード
import anthropic
client = anthropic.Anthropic()
# 履歴に対して圧縮を有効化
response = client.messages.create(
model="claude-3-opus-20260205",
messages=[
{"role": "user", "content": "..."},
{"role": "assistant", "content": "..."}
],
# 2026年新機能: 10ターン以上前の履歴を自動圧縮
compaction_threshold="auto",
system="あなたは親切なアシスタントです。"
)
3. 「階層別コンテキスト」ガード(Gemini 3.0ロジック)
意図しない支出の急増を防ぐ設定スクリプト。
# Gemini 3.0 Proの20万トークン超え価格段差を回避するロジック
def select_model_tier(input_text):
token_count = count_tokens(input_text)
if token_count > 195000: # 安全マージン
print("警告: 長文コンテキスト価格階層(4.00ドル/100万トークン)に近づいています。")
# まずRAG要約にフォールバック
return perform_rag_summarization(input_text)
else:
return call_gemini_3_pro(input_text)
4. 「文書比較器」(長文コンテキストの特化用途)
RAGは「文書Aと文書Bを比較せよ」が苦手。これにはGPT-5.3 Codexの操縦性を活用する。
ROLE: 上級法務アナリスト(GPT-5.3 Codex)。
TASK: 文書Aと文書Bの「責任条項」を比較する。
指示:
1. 両文書を完全にコンテキストに読み込む(コンテキストウィンドウ: 20万トークン)。
2. 両方の責任条項を特定する。
3. 責任上限、補償、管轄権における明確な違いをリスト化する。
4. 中断モード: 曖昧な条項を見つけた場合、先に進む前に一時停止し、明確化を求める。
5. 「トピッククラスター」生成器(メタデータ強化)
長文コンテキストをオフラインで使用し、RAGインデックスのメタデータを改善する。
ROLE: 司書/メタデータタガー。
TASK: 添付文書全体を読む。「トピックタグ」のリストと3文の要約を生成する。
ユースケース:
これらのタグはベクトルデータベース(Pinecone/Weaviate)に注入され、検索検索を改善する。
出力 JSON:
{
"title": "文字列",
"summary": "文字列",
"tags": ["タグ1", "タグ2", "タグ3"],
"primary_entities": ["エンティティ1", "エンティティ2"]
}
6. 「分散-集約」要約器(Map-Reduce)
100万トークンをも超える大規模データセット(例:完全なコードベース)用。
ステップ1(Map): 「この100ページのセクションを要約せよ。API定義に焦点を当てよ。」
ステップ2(Map): 「次の100ページのセクションを要約せよ…」
…
ステップN(Reduce): 「10のセクション要約が提供される。これらを最終的な技術仕様書に統合せよ。アーキテクチャパターンを強調せよ。」
7. 「引用強制器」(幻覚対策)
大規模コンテキスト使用時に重要。モデルは事実を混ぜがちだからだ。
ROLE: コンプライアンス責任者。
TASK: 提供されたコンテキストを使用して、ユーザーの質問に答える。
制約:
書くすべての文は、[Xページ、Y段落]の形式の引用で終わらなければならない。
読み込まれたコンテキスト内に特定のページ参照が見つからない場合は、「データが見つかりません」と述べなければならない。
8. 「コンテキスト詰め込み」警告(レイテンシガード)
システムが過負荷かどうかを自己評価するプロンプト。
SYSTEM: あなたは効率的なアシスタントです。
チェック: 入力トークンを数える。
IF 入力トークン > 100,000 AND ユーザークエリが単純(例:「こんにちは」):
応答: 「非常に大きな文書が読み込まれていることに気づきました。コストと時間を節約するため、一般的な知識に基づいて回答しますか、それとも特に文書を読む必要がありますか?」
9. 「CoT」(連鎖思考)抽出器
Claude 4.6 Opusに「適応的思考」の予算を効果的に使わせる。
ROLE: 深層推論エンジン。
TASK: 文書内で{query}の答えを見つける。
思考設定:
- タイプ: 「適応的」
- 焦点: 「エンティティ間の依存関係を追跡」
プロセス:
1. まず、関連キーワードが出現するページ番号をリストする。
2. 次に、それらのページから特定の文を抽出する。
3. 最後に、答えを統合する。
10. 「一時的コンテキスト」リセット
長文コンテキストセッションでのプライバシーを確保する設定パターン。
# Python / LangChain設定
# 機密性の高いPIIデータについては、GeminiのキャッシュAPIを使用してコンテキストをキャッシュしないことを保証する。
if "CONFIDENTIAL" in document_metadata:
# ストレージコスト(4.50ドル/100万トークン/時間)とセキュリティリスクを避けるためキャッシュを無効化
cache_mode = "disabled"
else:
cache_mode = "enabled" # 公開文書はキャッシュ許可
ベストプラクティス:「コンテキストを意識した」アーキテクチャ
2026年を生き抜くには、「検索優先、コンテキスト第二」の考え方を採用しなければならない。
すべきこと
- Gemini 3.0コンテキストキャッシュを使う: 頻繁にクエリする静的ライブラリ(例:コードベース)がある場合、ストレージ料金(4.50ドル/100万トークン/時間)を払ってホット状態を保つ。これにより後続のクエリがより安く、速くなる。
- 「既知の未知」にはRAGを使う: ユーザーが「SKU-123の価格は?」と尋ねたら、ベクトル検索を使う。これは決定的で安価だ。
- 「未知の未知」には長文コンテキストを使う: ユーザーが「これらの50の契約書に隠されたリスクは何か?」と尋ねたら、ベクトル検索は失敗する。これがClaude 4.6 Opusのキラー用途だ。
すべきでないこと
- 盲目的に「詰め込まない」: 会話履歴全体をデフォルトでコンテキストに送らない。Claudeの圧縮APIを使ってコンテキストウィンドウをリーンに保つ。
- 「階層の崖」を無視しない: トークン数を監視する。Gemini 3.0で19.9万トークンから20.1万トークンに跨ぐと、実質的に請求額が2倍になる。
「コンテキストエンジニアリング」の時代
「RAG対長文コンテキスト」の議論は時代遅れだ。勝者はコンテキストエンジニアリングである。
2027年までに、最高のAIアーキテクトは、データをコールドストレージ(ベクトルDB)、ウォームストレージ(コンテキストキャッシュ)、ホットコンピュート(推論)の間で流動的に移動させるシステムを設計できる者たちになるだろう。
コンテキストウィンドウをゴミ箱として扱うのをやめよ。高価値のワークスペースとして扱え。
次のステップ:
現在のGemini API設定を確認せよ。20万トークン未満階層最適化ロジック(プロンプト#3)を使用していなければ、おそらく100%過払いしている。今日からルーターを実装せよ。