On February 5th, the AI landscape shifted again. Claude 4.6 Opus and GPT-5.3 Codex launched simultaneously, both boasting massive 1-million-token context windows and “agentic reasoning” capabilities. Combined with Google’s Gemini 3.0 Pro, the boardrooms are buzzing with the same dangerous narrative we heard in 2024: “RAG is dead. Just dump the whole database into the prompt.”
Do not fall for it.
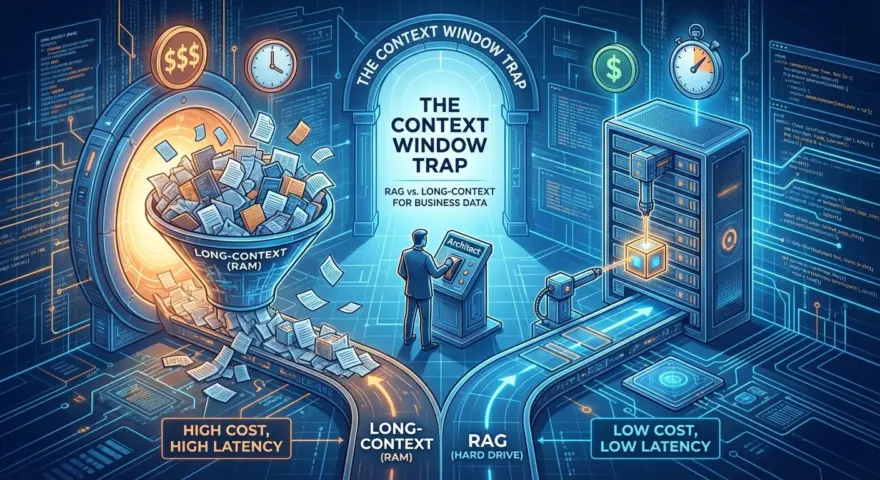
The Context Window Trap is the mistaken belief that because Gemini 3.0 can ingest a 2,000-page compliance manual, it should. While these frontier models have normalized megabyte-scale inputs, relying on them exclusively for enterprise data retrieval is a fast track to OpEx bankruptcy and latency hell.
For the Enterprise Architect, the choice between RAG (Retrieval-Augmented Generation) and Long-Context Inference is an optimization problem. RAG is your Hard Drive (cheap, vast, static). Long-Context is your RAM (expensive, volatile, fast).
This guide dissects the unit economics of the February 2026 model stack and provides the hybrid blueprints to survive the trap.
The Economics of Scale: Why “Lazy” Architectures Fail
The allure of Long-Context is simplicity. You remove the Vector Database and the chunking pipelines. You just paste the data.
But here is the math that kills that dream, based on this week’s new pricing sheets.
1. The “Context Tier” Penalty (Gemini 3.0 Pro)
Google’s pricing strategy for Gemini 3.0 Pro introduces a “Context Tax.”
- Standard Context (<200k tokens): $2.00 / 1M input tokens.
- Long Context (>200k tokens): $4.00 / 1M input tokens.
If you lazily dump a 300k-token manual into the context, your input costs double instantly. For a Customer Support agent handling 10,000 queries a day, this “lazy tax” compounds into millions of dollars annually.
2. The High Cost of “Opus-Class” Reasoning (Claude 4.6)
Claude 4.6 Opus is a masterpiece of reasoning, but it costs $5.00 per million input tokens.
If you feed it a 50-page document (approx. 25k tokens) for every query:
- Per Query Cost: ~$0.12 just to read the preamble.
- RAG Alternative: Retrieve only the relevant 1k tokens -> Cost: ~$0.005.
- The Result: RAG is 24x cheaper per interaction.
3. Latency & The “Lost in the Middle”
Even with GPT-5.3 Codex‘s reported 25% speed increase over its predecessor, processing 1M tokens still takes seconds. A RAG retrieval takes milliseconds. If your SLA demands sub-second responses, Long-Context is physically incapable of competing. Furthermore, despite improvements, “Needle in a Haystack” performance still degrades when the context is saturated with irrelevant noise (entropy).
The Blueprint: 10 Elite Prompts / Configurations
To navigate this trap, you need a Hybrid Architecture. The following prompts and configurations act as the routing logic, enabling your system to switch between RAG and Long-Context dynamically.
1. The “Traffic Cop” Router (The Decision Node)
This is the most critical component. It analyzes the user query to decide if it needs a full document scan (Long Context) or a specific fact lookup (RAG).
ROLE: Query Optimization Agent.
TASK: Classify the user query to determine the retrieval strategy.
STRATEGIES:
1. "SPECIFIC_RETRIEVAL" (RAG): For queries asking for specific facts, numbers, dates, or single-entity details. (Routes to Gemini 3.0 Flash or Index).
2. "GLOBAL_ANALYSIS" (Long-Context): For queries asking for summaries, themes, comparisons across the whole text, or "how-to" guides requiring full context. (Routes to Claude 4.6 Opus).
INPUT: {user_query}
OUTPUT JSON:
{
"strategy": "SPECIFIC_RETRIEVAL" | "GLOBAL_ANALYSIS",
"reasoning": "Query asks for a specific invoice number, which is a needle lookup."
}
2. The Context Compaction Configuration (Claude 4.6 Style)
Claude 4.6 Opus introduced a “Context Compaction” API. Use this to summarize conversation history automatically instead of paying to re-read raw logs.
# Pseudo-code for Anthropic Compaction API
import anthropic
client = anthropic.Anthropic()
# Enable Compaction on the history
response = client.messages.create(
model="claude-3-opus-20260205",
messages=[
{"role": "user", "content": "..."},
{"role": "assistant", "content": "..."}
],
# New 2026 Feature: Auto-compact history older than 10 turns
compaction_threshold="auto",
system="You are a helpful assistant."
)
3. The “Tiered Context” Guard (Gemini 3.0 Logic)
A configuration script to prevent accidental spending jumps.
# Logic to avoid the >200k pricing cliff on Gemini 3.0 Pro
def select_model_tier(input_text):
token_count = count_tokens(input_text)
if token_count > 195000: # Buffer for safety
print("WARNING: Approaching Long-Context Pricing Tier ($4.00/1M).")
# Fallback to RAG summarization first
return perform_rag_summarization(input_text)
else:
return call_gemini_3_pro(input_text)
4. The “Document Comparator” (Long-Context Specialty)
RAG is terrible at “Compare Document A vs Document B”. Use GPT-5.3 Codex’s steerability for this.
ROLE: Senior Legal Analyst (GPT-5.3 Codex).
TASK: Compare the "Liability Clause" in Document A versus Document B.
INSTRUCTIONS:
1. Load both documents fully into context (Context Window: 200k).
2. Identify the Liability Clause in both.
3. List distinct differences in liability caps, indemnification, and jurisdiction.
4. INTERRUPT MODE: If you find a clause that is ambiguous, pause and ask for clarification before proceeding.
5. The “Topic Cluster” Generator (Metadata Enrichment)
Use Long-Context offline to generate better metadata for your RAG index.
ROLE: Librarian / Metadata Tagger.
TASK: Read the entire attached document. Generate a list of "Topic Tags" and a 3-sentence summary.
USE CASE:
These tags will be injected into a Vector Database (Pinecone/Weaviate) to improve search retrieval.
OUTPUT JSON:
{
"title": "string",
"summary": "string",
"tags": ["tag1", "tag2", "tag3"],
"primary_entities": ["entity1", "entity2"]
}
6. The “Scatter-Gather” Summarizer (Map-Reduce)
For massive datasets exceeding even 1M tokens (e.g., full codebases).
STEP 1 (Map): "Summarize this 100-page section. Focus on API definitions."
STEP 2 (Map): "Summarize the next 100-page section..."
...
STEP N (Reduce): "You are provided with 10 section summaries. Synthesize them into a final Technical Specification. Highlight architectural patterns."
7. The “Citation Enforcer” (Anti-Hallucination)
Crucial when using large contexts, as models tend to blend facts.
ROLE: Compliance Officer.
TASK: Answer the user's question using the provided context.
CONSTRAINT:
Every single sentence you write MUST end with a citation in the format [Page X, Paragraph Y].
If you cannot find the specific page reference in the loaded context, you must state "Data not found."
8. The “Context Stuffing” Warning (Latency Guard)
A prompt for the system to self-assess if it’s overloaded.
SYSTEM: You are an efficient assistant.
CHECK: Count the input tokens.
IF input_tokens > 100,000 AND user_query is simple (e.g., "Hi"):
RESPONSE: "I notice you've loaded a very large document. To save costs and time, would you like me to answer based on general knowledge, or do you specifically need me to read the document?"
9. The “CoT” (Chain of Thought) Extractor
Forces Claude 4.6 Opus to use its “Adaptive Thinking” budget effectively.
ROLE: Deep Reasoning Engine.
TASK: Find the answer to {query} in the document.
THINKING_CONFIG:
- Type: "Adaptive"
- Focus: "Trace dependencies between entities"
PROCESS:
1. First, list the page numbers where relevant keywords appear.
2. Second, extract the specific sentences from those pages.
3. Third, synthesize the answer.
10. The “Ephemeral Context” Reset
A configuration pattern to ensure privacy in long-context sessions.
# Python / LangChain configuration
# Ensure that for sensitive PII data, the context is NOT cached using Gemini's Caching API.
if "CONFIDENTIAL" in document_metadata:
# Disable caching to avoid storage costs ($4.50/1M/hour) and security risks
cache_mode = "disabled"
else:
cache_mode = "enabled" # Cache allowed for public docs
Best Practices: The “Context-Aware” Architecture
To survive in 2026, you must adopt a “Retrieval-First, Context-Second” mindset.
Do’s
- Do use Gemini 3.0 Context Caching: If you have a static library (e.g., a codebase) you query often, pay the storage fee ($4.50/1M tokens/hour) to keep it hot. It makes subsequent queries cheaper and faster.
- Do use RAG for “Known Unknowns”: If the user asks “What is the price of SKU-123?”, use Vector Search. It is deterministic and cheap.
- Do use Long-Context for “Unknown Unknowns”: If the user asks “What risks are hidden in these 50 contracts?”, Vector Search will fail. This is the killer use case for Claude 4.6 Opus.
Don’ts
- Don’t “Stuff” blindly: Do not default to sending the entire conversation history into the context. Use Claude’s Compaction API to keep the context window lean.
- Don’t ignore the “Tier Cliff”: Monitor your token counts. Crossing from 199k to 201k tokens on Gemini 3.0 effectively doubles your bill.
The “Context-Engineering” Era
The debate “RAG vs. Long Context” is obsolete. The winner is Context Engineering.
By 2027, the best AI Architects will be those who can design systems that fluidly move data between Cold Storage (Vector DBs), Warm Storage (Context Caching), and Hot Compute (Inference).
Stop treating the Context Window as a dumpster. Treat it as a high-value workspace.
Your Next Step:
Check your current Gemini API configuration. If you aren’t using the <200k token tier optimization logic (Prompt #3), you are likely overpaying by 100%. Implement the router today.