PPOとDPOに別れを:GRPO、DAPO、GSPO徹底解説 —— 次世代LLMアライメント技術スタック
2023年から2024年にかけて、RLHF(Reinforcement Learning from Human Feed…
Empowering Developers with AI Prompts and Tools

2023年から2024年にかけて、RLHF(Reinforcement Learning from Human Feed…
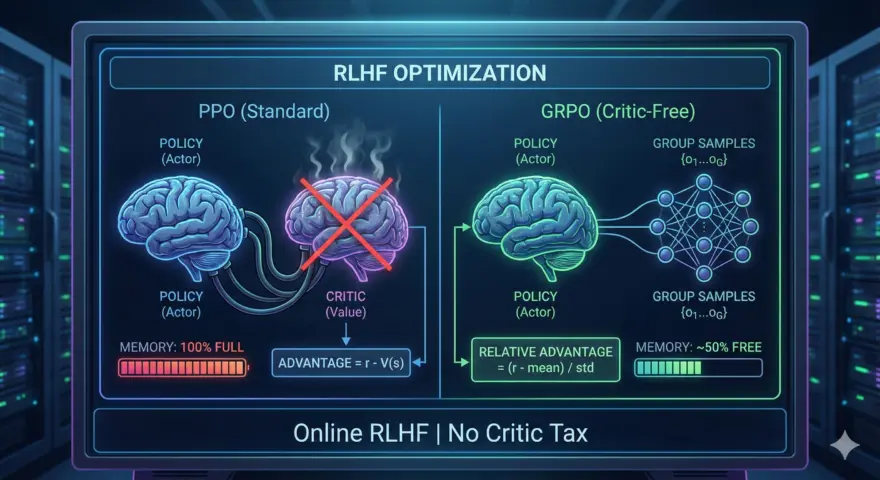
ボトルネック: PPOのメモリコストとDPOの限界 長年、Proximal Policy Optimization (P…

ボトルネック:「知能 vs 速度」というデッドロック 過去2年間、プロダクションレベルのAIエージェントを構築する際、エ…

ボトルネック:もはやモデルだけの問題ではない 2026年、生成AIにおける課題は「動くモデルを見つけること」ではなく、「…

大規模言語モデル(LLM)を取り巻くエンジニアリング領域は、散在する実験的なスクリプトの寄せ集めから、堅牢で多層的なソフ…

技術的ボトルネック: 推論コストが予算を圧迫していませんか?「2+2は?」といった単純な質問から、複雑なRAG(検索拡張…
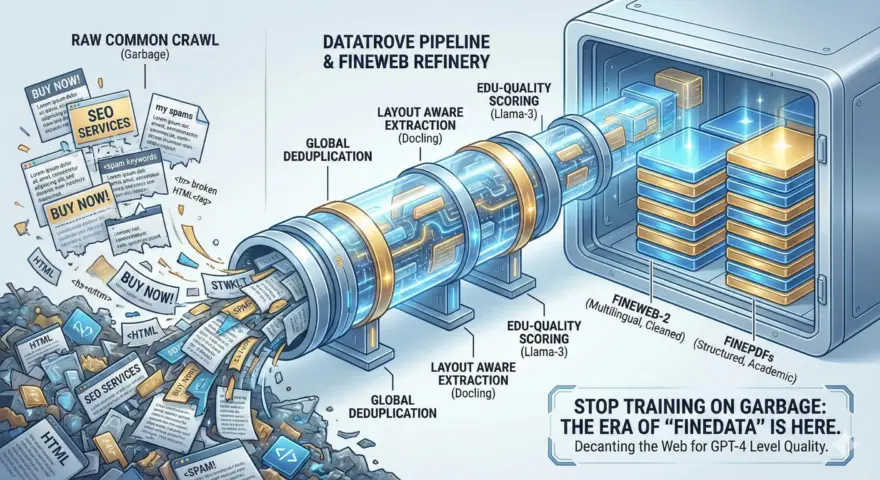
モデルの知能は、モデルが消費するトークンの質で決まる。2025年後半の今になっても、生のCommon Crawlを使って…

U-Netの支配は終わった。2025年の生成AI革命を支えるアーキテクチャ、それがここにある。 長年にわたり、U-Net…

ロングコンテキストAIが、より速く、そして圧倒的に安くなりました。 2025年12月1日、DeepSeek-V3.2 の…
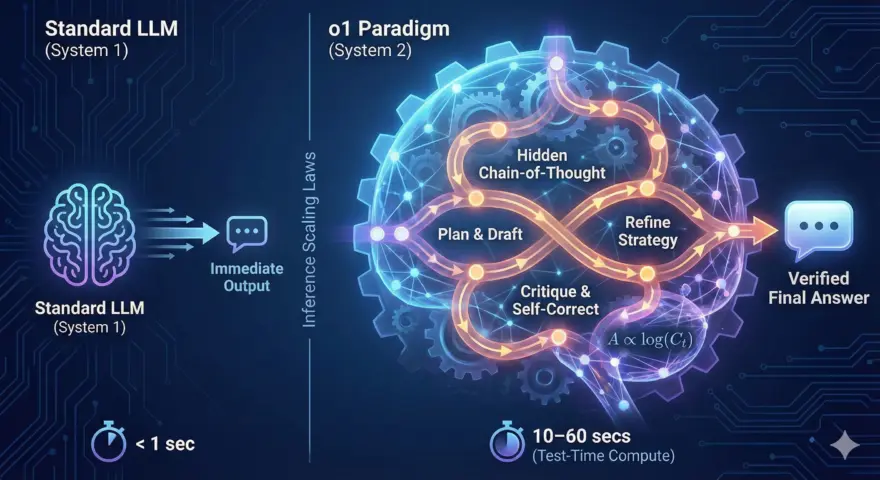
もしあなたがOpenAIの oシリーズ(o1, o3, o4など) のモデルを使ったことがあるなら、ある「不穏な」挙動に…