Your model is only as smart as the tokens it consumes. If you are still using raw Common Crawl in late 2025, you are burning compute on noise.
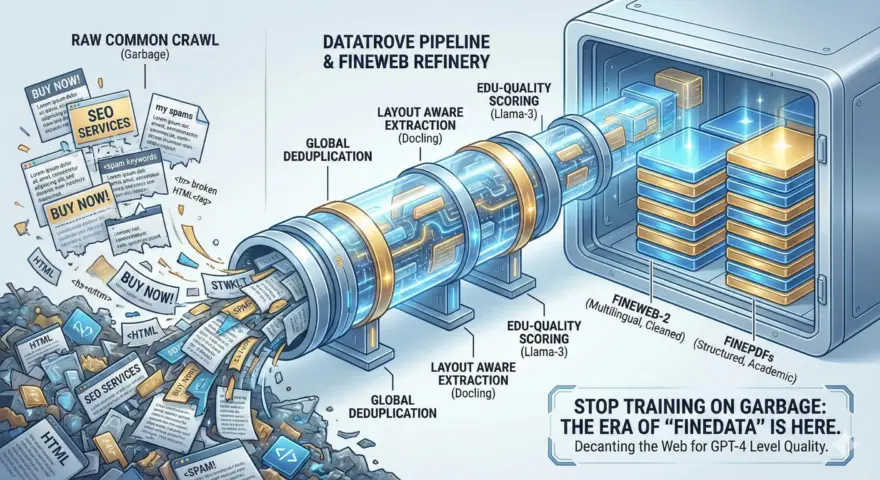
The biggest bottleneck in open-source AI today isn’t parameter count or context length—it is data hygiene. While proprietary labs carefully decant their datasets to remove SEO spam, duplicates, and incoherence, the open-source community has historically relied on “massive but dirty” dumps like standard Common Crawl.
This changes with HuggingFaceFW’s release of the “Fine” suite: FineWeb-2, FineWeb-Edu, and FinePDFs. These aren’t just filtered datasets; they represent a fundamental shift in data engineering, moving from “maximum tokens” to “maximum signal.”
This post breaks down the architecture of this new standard, visualizes the processing pipeline, and provides the code to stream these petabyte-scale assets into your training loop.
Core Concept: The “FineData” Pipeline
The raw web is a mess of navigational boilerplate, SEO keyword stuffing, and low-quality machine-generated text. To create FineWeb, Hugging Face developed datatrove, a processing library designed to scale across thousands of CPU cores.
The difference between “Garbage” (Raw Common Crawl) and “FineData” lies in three specific stages:
- Global Deduplication (FineWeb-2): Unlike standard dumps that deduplicate per month, FineWeb-2 uses MinHash to deduplicate globally across 96 snapshots (2013–2024), retaining unique information while slashing redundancy.
- Optical & Layout Extraction (FinePDFs): Instead of naively stripping text from PDFs (which results in garbled headers and footers), FinePDFs uses Docling and vision-models to understand document layout, preserving the logical flow of high-value documents like papers and manuals.
- Semantic Quality Scoring (Edu): The pipeline uses an Llama-3-trained classifier to score content based on “educational value,” systematically purging low-intelligence content.
The Processing Architecture
graph TD
A["Raw Common Crawl (Petabytes)"] -->|"Ingest"| B["Datatrove Pipeline"]
B --> C{"Format Type"}
subgraph "Web Track (FineWeb-2)"
C -->|"HTML/Text"| D["Trafilatura Extraction"]
D --> E["Global MinHash Deduplication"]
E --> F["PII Removal & Heuristic Filtering"]
F --> G["Language ID (1000+ Langs)"]
end
subgraph "PDF Track (FinePDFs)"
C -->|"PDF Files"| H["Docling (Layout Aware)"]
H -->|"Fallback"| I["RolmOCR (Vision Model)"]
I --> J["Structure Restoration"]
end
G --> K["Unified Quality Gate"]
J --> K
K -->|"Llama-3 Annotation"| L["Edu-Score Classifier"]
L -->|"Score > 3"| M["FineWeb-Edu / FinePDFs"]
The Code: Streaming and Filtering
These datasets comprise trillions of tokens. Downloading them locally is impossible for most setups. You must leverage streaming via the Hugging Face datasets library.
1. Streaming FineWeb-2 (Multilingual)
Target: Efficiently loading specific languages without downloading the full 8TB corpus.
from datasets import load_dataset
# Configuration for FineWeb-2
# We target the specific language subset to save bandwidth
DATASET_ID = "HuggingFaceFW/fineweb-2"
LANG_CONFIG = "deu_Latn" # German
BUFFER_SIZE = 10_000
print(f"🌊 Initializing stream for {LANG_CONFIG}...")
# Stream mode enabled (streaming=True)
ds = load_dataset(
DATASET_ID,
name=LANG_CONFIG,
split="train",
streaming=True
)
# Shuffle buffer allows for random sampling from the stream
shuffled_ds = ds.shuffle(buffer_size=BUFFER_SIZE, seed=42)
print("🚀 Extracting high-quality samples:")
for i, sample in enumerate(shuffled_ds):
if i >= 3: break
# Metadata usually includes 'url', 'date', and 'dump_id'
meta = sample.get('meta', {})
print(f"\n--- Sample {i+1} [Date: {meta.get('date', 'N/A')}] ---")
print(sample['text'][:300] + "...")
2. The “Garbage Filter” (Edu Classifier)
If you are mixing in your own private data, you should apply the same quality standards as FineWeb. Hugging Face released the exact classifier used to build FineWeb-Edu.
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# The official BERT-based classifier used for FineWeb-Edu
MODEL_ID = "HuggingFaceTB/fineweb-edu-classifier"
print("⚙️ Loading Quality Classifier...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
model = AutoModelForSequenceClassification.from_pretrained(MODEL_ID)
def evaluate_quality(text):
"""Returns a score from 0 (Trash) to 5 (Textbook Quality)"""
inputs = tokenizer(text, return_tensors="pt", padding="longest", truncation=True)
with torch.no_grad():
outputs = model(**inputs)
# Squeeze raw logits to get score
logits = outputs.logits.squeeze(-1).float().numpy()
return logits[0]
# Example Usage
raw_texts = [
"The Navier–Stokes equations describe the motion of viscous fluid substances.", # High Value
"CLICK HERE for free iPhone!!! Best SEO services 2025...", # Garbage
]
print("\n📊 Quality Assessment:")
for t in raw_texts:
score = evaluate_quality(t)
status = "✅ KEEP" if score > 3 else "❌ DISCARD"
print(f"Score: {score:.2f} | {status} | Content: {t[:40]}...")
Step-by-Step Implementation
To build a competitive model in 2026, follow this data curation recipe:
- Establish the Base: Use FineWeb-Edu as your primary English foundation. It significantly outperforms un-filtered FineWeb on benchmarks like MMLU and ARC.
- Inject Knowledge: Mix in FinePDFs at a ratio of 10-15%. This provides the “long-context” reasoning often found in academic papers and technical manuals, which web crawls lack.
- Expand Globally: Use FineWeb-2 for multilingual capabilities. Warning: Do not blindly mix all languages. Curriculum learning (introducing languages in stages) often yields better stability.
- Apply Thresholding:
- For reasoning tasks: Only train on samples with an Edu Score
> 3.5. - For creative tasks: Lower the threshold to
> 2.0to retain stylistic diversity, but strictly filter NSFW/spam clusters.
- For reasoning tasks: Only train on samples with an Edu Score
The release of FineWeb-2 and FinePDFs marks the end of the “Quantity over Quality” era in open-source AI. We now have public access to datasets that rival the internal moats of top-tier labs.
The hardware barrier remains, but the data barrier has crumbled. Stop training on garbage; the refined fuel is right here.