ボトルネック: PPOのメモリコストとDPOの限界
長年、Proximal Policy Optimization (PPO) はRLHF(人間からのフィードバックによる強化学習)のデファクトスタンダードとして君臨してきました。しかし、これには甚大なインフラコストが伴います。事実上、Actor(アクター)、Critic(クリティック)、Reference(参照)、Reward Model(報酬モデル)という4つのモデルをVRAMに展開する必要があるからです。70Bパラメータ級のモデルにおいては、これは巨大なラボ以外でのファインチューニングを不可能にします。
Direct Preference Optimization (DPO) は、強化学習のループを完全に排除し、アライメントを好みのペアに対する教師あり分類問題として扱うことでメモリ問題を解決しました。しかし、DPOは Chain-of-Thought (CoT: 思考の連鎖) の最適化 に苦戦します。DPOは静的なデータセットに依存しており、モデルが自ら推論パスを「探索(Explore)」することを本質的に促さないからです。
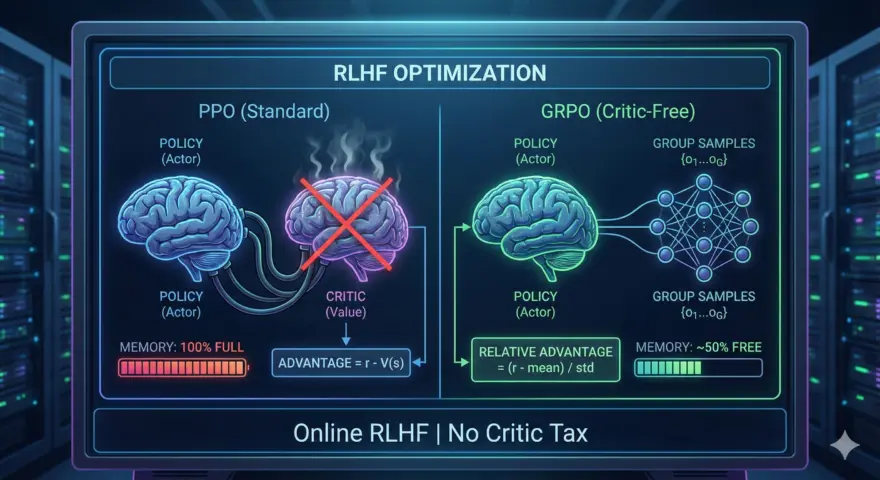
そこで登場するのが Group Relative Policy Optimization (GRPO) です。DeepSeekのR1/V3に関する研究 によって一般化されたGRPOは、Criticモデルを完全に排除します。価値関数を推定する代わりに、1つのプロンプトに対して複数の出力グループを生成し、報酬を計算し、その グループ平均 をベースラインとして使用します。これにより、RL(強化学習)の探索的利点を維持しながらVRAM使用量を劇的に削減できるため、数学的推論やコーディング推論の最適化において優れた選択肢となります。
アーキテクチャ: GRPOはいかにして価値関数を排除するか
標準的なPPOでは、価値ネットワーク(Critic)を使用してアドバンテージ関数 $A_t$ を計算します。GRPOはこれを、サンプリングされた出力グループの平均報酬で代替します。
アルゴリズム
- サンプリング: 各プロンプト $q$ に対して、古いポリシー $\pi_{\theta_{old}}$ から $G$ 個の出力グループ ${o_1, o_2, …, o_G}$ をサンプリングします。
- スコアリング: 報酬モデル(またはルールベースの検証器)を適用して、報酬 $r_1, …, r_G$ を取得します。
- アドバンテージ計算: グループ内での相対的なパフォーマンスに基づいて、各出力のアドバンテージを計算します。
- 最適化: GRPOの目的関数を最大化します。これには、モデルを参照ポリシーに近づけるためのKLダイバージェンス(距離)ペナルティが含まれます。
ワークフローの可視化
graph TD
subgraph "GRPO Workflow"
A["入力プロンプト (q)"] --> B{"Policyモデル"}
B --"G個の出力をサンプリング"--> C["出力群 {o1, o2... oG}"]
C --> D["報酬関数 / Verifier"]
D --"報酬の計算"--> E["グループ平均・標準偏差の算出"]
E --> F["アドバンテージ (Ai) の計算"]
F --> G["Policyの更新 (Criticネットワーク不要)"]
end
subgraph "Legacy PPO"
X["入力"] --> Y["Actor"]
X --> Z["Critic (Value Net)"]
Y --> R["報酬 (Reward)"]
R & Z --> CALC["GAE 推定"]
end
実装
ここでは、グループ相対戦略のサポートを最近統合した Hugging Face TRL (Transformer Reinforcement Learning) ライブラリを使用してGRPOを実装します。
前提条件
- ハードウェア: 7B-14BモデルならA100 (80GB) 1枚で十分です。GRPOはメモリ効率に優れています。
- ライブラリ:
trl>=0.11.0,transformers,torch.
Python実装
このスクリプトは、ニューラル報酬モデルの代わりに決定論的な報酬関数(「Verifier: 検証器」)を使用して、数学の問題に対してモデルをアライメントするデモです。これはDeepSeek-Mathのアプローチを反映しています。
import torch
from datasets import load_dataset
from trl import GRPOTrainer, GRPOConfig
from transformers import AutoTokenizer, AutoModelForCausalLM
# 1. 設定 (Configuration)
# 注意: Criticモデルはロードしません。
MODEL_ID = "deepseek-ai/deepseek-coder-6.7b-instruct"
OUTPUT_DIR = "./grpo-reasoning-adapter"
training_args = GRPOConfig(
output_dir=OUTPUT_DIR,
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=2,
learning_rate=5e-6,
beta=0.04, # KLペナルティ係数
max_grad_norm=1.0,
logging_steps=10,
save_strategy="steps",
# GRPO特有の設定
num_generations=8, # グループサイズ (G)。大きいほどベースライン推定は正確になるがVRAMを消費する。
max_completion_length=512,
bf16=True
)
# 2. 報酬関数 (The Verifier)
# このシナリオでは単純な算術チェッカーを使用します。
# 本番環境では、モデルの <answer> タグをパースして正解と比較するロジックになります。
def arithmetic_reward_func(prompts, completions, answer, **kwargs):
rewards = []
for comp, true_ans in zip(completions, answer):
# ヒューリスティック: 正解の数字が出力に含まれているかチェック
# DeepSeekでは厳密なパース処理を行います。
score = 1.0 if str(true_ans) in comp else 0.0
# シェイピング: 不正解なのに極端に冗長な場合はペナルティを与える
if score == 0.0 and len(comp) > 200:
score -= 0.1
rewards.append(score)
return rewards
# 3. データとモデルのロード
dataset = load_dataset("gsm8k", "main", split="train[:1%]") # デモ用の極小サブセット
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
tokenizer.pad_token = tokenizer.eos_token
# 必要に応じて4-bitでロードしてさらにメモリを節約
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
torch_dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2"
)
# 4. GRPO Trainerの初期化
trainer = GRPOTrainer(
model=model,
reward_processing_class=tokenizer, # トークナイズ処理を内部で行う
args=training_args,
train_dataset=dataset,
reward_funcs=arithmetic_reward_func, # 複数の報酬関数を設定可能
)
# 5. トレーニングの実行
if __name__ == "__main__":
print(f"Starting GRPO with Group Size: {training_args.num_generations}")
trainer.train()
trainer.save_model(OUTPUT_DIR)
実装ステップ
- Verifier(検証器)の定義: 好みのデータセット(Chosen vs Rejected)を必要とするDPOとは異なり、GRPOは プロンプト と 正解データ(Ground Truth) を必要とします。
reward_funcsのロジックが極めて重要です。コーディングタスクなら単体テストを実行し、数学なら数値の等価性をチェックします。 - グループサイズ ($G$) の設定:
GRPOConfig内のnum_generationsパラメータで $G$ を制御します。- 低 $G$ (例: 4): アドバンテージ推定の分散が大きくなります。
- 高 $G$ (例: 16+): ベースラインは安定しますが、トレーニング中の推論コストが線形に増加します。
- Beta ($\beta$) の調整: GRPOにおけるKLペナルティの挙動はDPOとは異なります。標準的な
0.1ではなく、DeepSeek-Math に倣い0.04程度から開始してください。 - フォーマット処理: 報酬関数が確実に答えを抽出できるよう、モデルに対して厳密なフォーマット(例: 「最終回答は
\boxed{}の中に入れてください」)で出力するようプロンプトを設計してください。
比較: GRPO vs 他手法
| 機能 | PPO | DPO | GRPO |
|---|---|---|---|
| VRAM内モデル数 | 4 (Actor, Critic, Ref, RM) | 2 (Policy, Ref) | 2 (Policy, Ref) |
| データ要件 | 好みのペア または 報酬信号 | 好みのペア (オフライン) | プロンプト + 評価器 (Evaluator) |
| 推論能力 | 高 (探索が可能) | 低 (オフラインでの模倣) | 高 (グループ生成による探索) |
| 安定性 | 低 (ハイパーパラメータに敏感) | 高 | 中〜高 |
| 最適なユースケース | 一般的なチャット | チャット / スタイル変換 | 数学, ロジック, コード |
GRPOは、プロキシベースの最適化(人間が何を好むかを推測する報酬モデルの学習)から、アウトカムベースの最適化(答えが実際に正しいかどうかを確認する)へのシフトを象徴しています。Criticを排除することでVRAMの約30〜40%を解放し、より大きなモデルの学習やバッチサイズの増加を可能にします。
2026年の推論重視のワークロードにおいて、DPOは「スタイル」のためであり、GRPOは「正確さ」のためにあります。