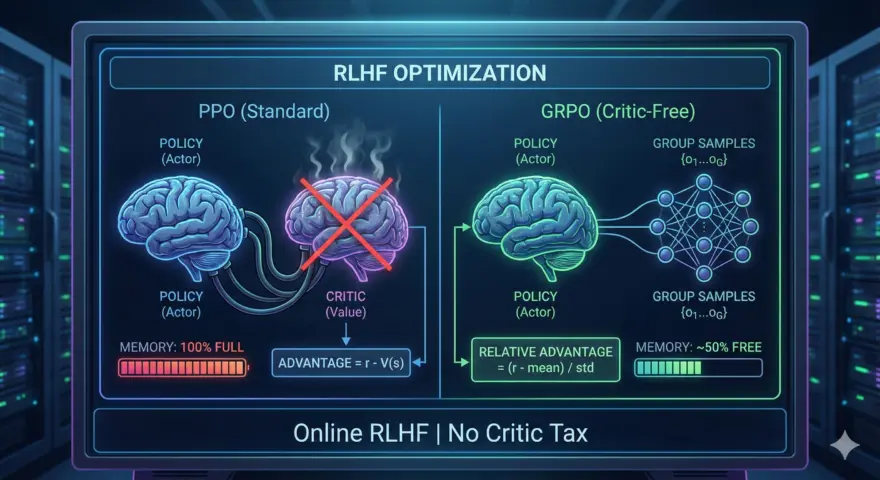
The Bottleneck: PPO’s Memory Tax and DPO’s Limitations
For years, Proximal Policy Optimization (PPO) was the gold standard for RLHF. However, it imposes a massive infrastructure tax: you effectively need to load four models into VRAM (Actor, Critic, Reference, and Reward Model). For 70B+ parameter models, this makes fine-tuning prohibitive for all but the largest labs.
Direct Preference Optimization (DPO) solved the memory issue by removing the reinforcement learning loop entirely, treating alignment as a supervised classification problem on preference pairs. However, DPO struggles with chain-of-thought (CoT) optimization. It relies on static datasets and doesn’t inherently encourage the model to explore reasoning paths.
Enter Group Relative Policy Optimization (GRPO). Popularized by DeepSeek’s R1/V3 research, GRPO removes the Critic model entirely. Instead of estimating a value function, it generates a group of outputs for a single prompt, calculates the rewards, and uses the group average as the baseline. This reduces VRAM usage significantly while preserving the exploration benefits of RL, making it the superior choice for optimizing mathematical and coding reasoning.
The Architecture: How GRPO Eliminates the Value Function
In standard PPO, the Advantage function $A_t$ is calculated using a value network (Critic). GRPO substitutes this with the mean reward of a group of sampled outputs.
The Algorithm
- Sampling: For each prompt $q$, sample a group of $G$ outputs ${o_1, o_2, …, o_G}$ from the old policy $\pi_{\theta_{old}}$.
- Scoring: Apply a reward model (or rule-based verifier) to get rewards $r_1, …, r_G$.
- Advantage Calculation: Compute the advantage for each output based on its relative performance within the group.
- Optimization: Maximize the GRPO objective, which includes the KL-divergence penalty to keep the model close to the reference policy.
Visualizing the Workflow
graph TD
subgraph "GRPO Workflow"
A["Input Prompt (q)"] --> B{"Policy Model"}
B --"Sample G outputs"--> C["Outputs {o1, o2... oG}"]
C --> D["Reward Function / Verifier"]
D --"Calculate Rewards"--> E["Compute Group Mean & Std"]
E --> F["Calculate Advantage (Ai)"]
F --> G["Update Policy (No Critic Network)"]
end
subgraph "Legacy PPO"
X["Input"] --> Y["Actor"]
X --> Z["Critic (Value Net)"]
Y --> R["Reward"]
R & Z --> CALC["GAE Estimation"]
end
The Implementation
We will implement GRPO using the Hugging Face TRL (Transformer Reinforcement Learning) library, which recently integrated support for group-relative strategies.
Prerequisites
- Hardware: A single A100 (80GB) or equivalent for 7B-14B models. GRPO is memory efficient.
- Libraries:
trl>=0.11.0,transformers,torch.
Python Implementation
This script demonstrates aligning a model on math problems using a deterministic reward function (the “verifier”) rather than a neural reward model. This mirrors the DeepSeek-Math approach.
import torch
from datasets import load_dataset
from trl import GRPOTrainer, GRPOConfig
from transformers import AutoTokenizer, AutoModelForCausalLM
# 1. Configuration
# Note: We do NOT load a Critic model.
MODEL_ID = "deepseek-ai/deepseek-coder-6.7b-instruct"
OUTPUT_DIR = "./grpo-reasoning-adapter"
training_args = GRPOConfig(
output_dir=OUTPUT_DIR,
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=2,
learning_rate=5e-6,
beta=0.04, # KL penalty coefficient
max_grad_norm=1.0,
logging_steps=10,
save_strategy="steps",
# GRPO Specifics
num_generations=8, # The group size (G). Higher = better baseline estimation but more VRAM.
max_completion_length=512,
bf16=True
)
# 2. Reward Function (The Verifier)
# In this scenario, we use a simple arithmetic checker.
# In production, this would parse the model's <answer> tag and compare to ground truth.
def arithmetic_reward_func(prompts, completions, answer, **kwargs):
rewards = []
for comp, true_ans in zip(completions, answer):
# Heuristic: Check if the ground truth number appears in the output
# DeepSeek uses rigorous parsing logic here.
score = 1.0 if str(true_ans) in comp else 0.0
# Shaping: Penalize extreme verbosity if incorrect
if score == 0.0 and len(comp) > 200:
score -= 0.1
rewards.append(score)
return rewards
# 3. Load Data & Model
dataset = load_dataset("gsm8k", "main", split="train[:1%]") # Tiny subset for demo
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
tokenizer.pad_token = tokenizer.eos_token
# Load Model in 4-bit to save further memory if needed
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
torch_dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2"
)
# 4. Initialize GRPO Trainer
trainer = GRPOTrainer(
model=model,
reward_processing_class=tokenizer, # Handles tokenization internally
args=training_args,
train_dataset=dataset,
reward_funcs=arithmetic_reward_func, # Can accept multiple reward functions
)
# 5. Execute Training
if __name__ == "__main__":
print(f"Starting GRPO with Group Size: {training_args.num_generations}")
trainer.train()
trainer.save_model(OUTPUT_DIR)
Implementation Steps
- Define the Verifier: Unlike DPO which needs a preference dataset (Chosen vs Rejected), GRPO requires a prompt and a ground truth. The
reward_funcslogic is critical. For coding, this runs unit tests; for math, this checks numerical equivalence. - Set Group Size ($G$): In
GRPOConfig, thenum_generationsparameter controls $G$.- Low $G$ (e.g., 4): High variance in advantage estimation.
- High $G$ (e.g., 16+): Better baseline, but linearly increases inference cost during training.
- Tune Beta ($\beta$): The KL penalty acts differently in GRPO than DPO. Start with
0.04(as per DeepSeek-Math) rather than the standard0.1. - Format Handling: Ensure your model is prompted to output strictly formatted answers (e.g., “Put the final answer in
\boxed{}“) so the reward function can extract it reliably.
Comparison: GRPO vs. The Rest
| Feature | PPO | DPO | GRPO |
|---|---|---|---|
| Models in VRAM | 4 (Actor, Critic, Ref, RM) | 2 (Policy, Ref) | 2 (Policy, Ref) |
| Data Requirement | Preference Pairs or Reward Signal | Preference Pairs (Offline) | Prompts + Evaluator |
| Reasoning Capability | High (Exploration allowed) | Low (Offline cloning) | High (Exploration via Group) |
| Stability | Low (Sensitive to hyperparameters) | High | Medium-High |
| Best Use Case | General Chat | Chat / Style Transfer | Math, Logic, Code |
GRPO represents a shift from proxy-based optimization (training a Reward Model to guess what humans like) to outcome-based optimization (checking if the answer is actually correct). By removing the Critic, you free up roughly 30-40% of your VRAM, allowing you to train larger models or increase batch sizes.
For 2026’s reasoning-heavy workloads, DPO is for style; GRPO is for correctness.