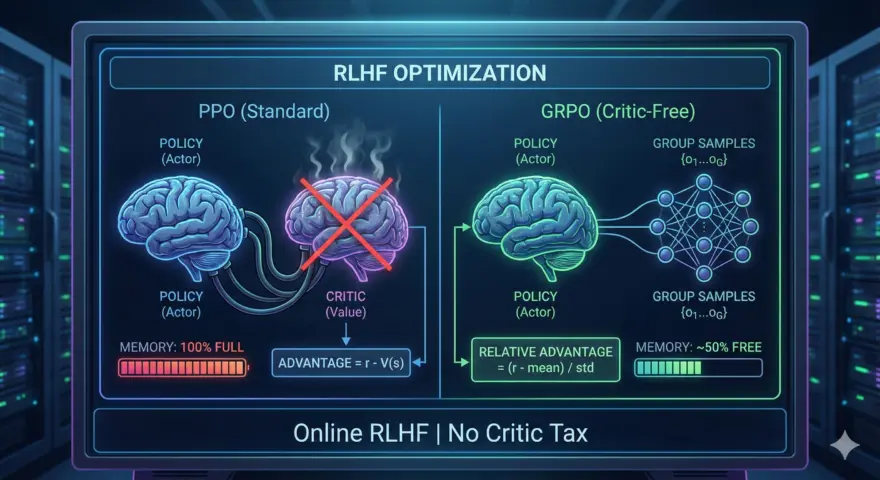
병목(Bottleneck): PPO의 메모리 비용과 DPO의 한계
수년 동안 Proximal Policy Optimization (PPO)는 RLHF(인간 피드백 기반 강화학습)의 표준이었습니다. 하지만 PPO는 막대한 인프라 비용을 요구합니다. VRAM에 4개의 모델(Actor, Critic, Reference, Reward Model)을 동시에 로드해야 하기 때문입니다. 이로 인해 70B 이상의 모델을 파인튜닝하는 것은 초대형 연구소가 아닌 이상 현실적으로 불가능했습니다.
Direct Preference Optimization (DPO)는 얼라인먼트 과정을 선호도 쌍(preference pairs)에 대한 지도 학습(supervised classification) 문제로 치환하여 강화학습 루프를 제거하고 메모리 문제를 해결했습니다. 하지만 DPO는 CoT(Chain-of-thought) 최적화에 취약합니다. 정적인 데이터셋에 의존하기 때문에 모델이 스스로 추론 경로를 탐색(Explore)하도록 유도하는 데 한계가 있습니다.
여기서 Group Relative Policy Optimization (GRPO)가 등장합니다. DeepSeek의 R1/V3 연구를 통해 널리 알려진 GRPO는 Critic 모델을 완전히 제거했습니다. 가치 함수(Value Function)를 추정하는 대신, 하나의 프롬프트에 대해 여러 개의 출력을 그룹으로 생성하고, 이들의 보상을 계산한 뒤 그룹 평균을 베이스라인으로 사용합니다. 이는 RL의 탐색(Exploration) 이점은 유지하면서 VRAM 사용량을 획기적으로 줄여주며, 특히 수학 및 코딩 추론 최적화에 탁월한 성능을 발휘합니다.
아키텍처: GRPO는 어떻게 가치 함수를 제거했는가
기존 PPO에서는 가치 네트워크(Critic)를 사용하여 어드밴티지 함수(Advantage function) $A_t$를 계산합니다. 반면, GRPO는 샘플링된 출력 그룹의 평균 보상을 통해 이를 대체합니다.
알고리즘 프로세스
- 샘플링 (Sampling): 각 프롬프트 $q$에 대해, 구 정책(Old Policy) $\pi_{\theta_{old}}$으로부터 $G$개의 출력 그룹 ${o_1, o_2, …, o_G}$을 샘플링합니다.
- 채점 (Scoring): 리워드 모델(혹은 규칙 기반 검증기)을 적용하여 보상 $r_1, …, r_G$를 얻습니다.
- 어드밴티지 계산 (Advantage Calculation): 그룹 내 상대적 성능을 기반으로 각 출력의 어드밴티지를 계산합니다.
- 최적화 (Optimization): GRPO 목적 함수를 최대화합니다. 여기에는 모델이 레퍼런스 정책(Reference Policy)에서 너무 멀어지지 않도록 하는 KL 발산(KL-divergence) 페널티가 포함됩니다.
워크플로우 시각화
graph TD
subgraph "GRPO 워크플로우"
A["입력 프롬프트 (q)"] --> B{"정책(Policy) 모델"}
B --"G개 출력 샘플링"--> C["출력값 그룹 {o1, o2... oG}"]
C --> D["보상 함수 / 검증기"]
D --"보상 계산"--> E["그룹 평균 & 표준편차 계산"]
E --> F["어드밴티지(Ai) 산출"]
F --> G["정책 업데이트 (Critic 없음)"]
end
subgraph "기존 PPO"
X["입력"] --> Y["Actor"]
X --> Z["Critic (Value Net)"]
Y --> R["Reward"]
R & Z --> CALC["GAE 추정"]
end
구현 (Implementation)
최근 그룹 상대적(Group-relative) 전략을 통합한 Hugging Face TRL (Transformer Reinforcement Learning) 라이브러리를 사용하여 GRPO를 구현해 보겠습니다.
사전 준비사항
- 하드웨어: 7B-14B 모델 기준 A100 (80GB) 1장. (GRPO는 메모리 효율이 높습니다.)
- 라이브러리:
trl>=0.11.0,transformers,torch.
Python 구현 코드
이 스크립트는 신경망 리워드 모델 대신 결정론적(deterministic) 보상 함수(일명 “검증기”)를 사용하여 수학 문제에 대해 모델을 정렬(Align)하는 방법을 보여줍니다. 이는 DeepSeek-Math의 접근 방식을 반영한 것입니다.
import torch
from datasets import load_dataset
from trl import GRPOTrainer, GRPOConfig
from transformers import AutoTokenizer, AutoModelForCausalLM
# 1. 설정 (Configuration)
# 참고: Critic 모델을 로드하지 않습니다.
MODEL_ID = "deepseek-ai/deepseek-coder-6.7b-instruct"
OUTPUT_DIR = "./grpo-reasoning-adapter"
training_args = GRPOConfig(
output_dir=OUTPUT_DIR,
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=2,
learning_rate=5e-6,
beta=0.04, # KL 페널티 계수
max_grad_norm=1.0,
logging_steps=10,
save_strategy="steps",
# GRPO 전용 설정
num_generations=8, # 그룹 크기 (G). 높을수록 베이스라인 추정이 정확하지만 VRAM 소모 증가.
max_completion_length=512,
bf16=True
)
# 2. 보상 함수 (검증기, The Verifier)
# 이 시나리오에서는 단순한 산술 검사기를 사용합니다.
# 실제 프로덕션에서는 모델의 <answer> 태그를 파싱하여 정답과 비교하는 로직이 들어갑니다.
def arithmetic_reward_func(prompts, completions, answer, **kwargs):
rewards = []
for comp, true_ans in zip(completions, answer):
# 휴리스틱: 정답(Ground Truth) 숫자가 출력에 포함되어 있는지 확인
# DeepSeek는 여기서 더 엄격한 파싱 로직을 사용합니다.
score = 1.0 if str(true_ans) in comp else 0.0
# 셰이핑(Shaping): 틀렸는데 출력이 너무 길면(변명 등) 페널티 부여
if score == 0.0 and len(comp) > 200:
score -= 0.1
rewards.append(score)
return rewards
# 3. 데이터 및 모델 로드
dataset = load_dataset("gsm8k", "main", split="train[:1%]") # 데모용 소량 데이터
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
tokenizer.pad_token = tokenizer.eos_token
# 메모리 절약을 위해 필요 시 4-bit 로드
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
torch_dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2"
)
# 4. GRPO 트레이너 초기화
trainer = GRPOTrainer(
model=model,
reward_processing_class=tokenizer, # 토크나이징 내부 처리
args=training_args,
train_dataset=dataset,
reward_funcs=arithmetic_reward_func, # 다수의 보상 함수 적용 가능
)
# 5. 학습 실행
if __name__ == "__main__":
print(f"Starting GRPO with Group Size: {training_args.num_generations}")
trainer.train()
trainer.save_model(OUTPUT_DIR)
구현 단계별 핵심 포인트
- 검증기(Verifier) 정의: DPO가 선호 데이터셋(Chosen vs Rejected)을 필요로 하는 것과 달리, GRPO는 프롬프트와 정답(Ground Truth)이 필요합니다.
reward_funcs로직이 핵심입니다. 코딩 모델의 경우 유닛 테스트를 실행하고, 수학 모델의 경우 수식의 등가성을 확인합니다. - 그룹 크기 ($G$) 설정:
GRPOConfig의num_generations파라미터가 $G$를 제어합니다.- 낮은 $G$ (예: 4): 어드밴티지 추정의 분산(Variance)이 커집니다.
- 높은 $G$ (예: 16+): 베이스라인 추정은 정확해지지만, 학습 중 인퍼런스 비용이 선형적으로 증가합니다.
- 베타($\beta$) 튜닝: GRPO의 KL 페널티는 DPO와 다르게 작동합니다. DeepSeek-Math 논문에 따르면, 일반적인
0.1대신0.04정도의 낮은 값에서 시작하는 것을 권장합니다. - 포맷 관리: 보상 함수가 정답을 안정적으로 추출할 수 있도록, 모델이
\boxed{}와 같이 엄격한 포맷으로 답을 출력하도록 프롬프팅해야 합니다.
비교: GRPO vs. 기타 알고리즘
| 특징 | PPO | DPO | GRPO |
|---|---|---|---|
| VRAM 내 모델 수 | 4 (Actor, Critic, Ref, RM) | 2 (Policy, Ref) | 2 (Policy, Ref) |
| 데이터 요구사항 | 선호 쌍(Preference Pairs) 또는 보상 시그널 | 선호 쌍 (오프라인) | 프롬프트 + 평가자(Evaluator) |
| 추론/탐색 능력 | 높음 (탐색 허용) | 낮음 (오프라인 모방) | 높음 (그룹 샘플링을 통한 탐색) |
| 학습 안정성 | 낮음 (하이퍼파라미터에 민감) | 높음 | 중간-높음 |
| 최적 사용 사례 | 일반 챗봇 | 챗봇 / 스타일 변환 | 수학, 논리, 코드 |
결론
GRPO는 프록시 기반 최적화(Reward Model을 학습시켜 인간이 무엇을 좋아할지 추측하는 것)에서 결과 기반 최적화(실제 정답이 맞는지 확인하는 것)로의 패러다임 전환을 의미합니다. Critic 모델을 제거함으로써 VRAM의 약 30-40%를 확보할 수 있으며, 이는 더 큰 모델을 학습시키거나 배치 사이즈를 키우는 데 사용할 수 있습니다.
2026년의 고난도 추론 워크로드에서, DPO가 스타일(Style)을 위한 것이라면 GRPO는 정확성(Correctness)을 위한 것입니다.