
기술적 병목 현상: 추론(Inference) 예산이 빠르게 소진되고 있습니다. “2+2는 무엇인가요?”와 같은 간단한 질문이든, 복잡한 RAG(검색 증강 생성) 합성 작업이든, 모든 쿼리가 가장 비싼 모델(예: DeepSeek-V3 또는 GPT-5.2)을 거치고 있습니다. 이러한 ‘하나로 전부 처리하는(One Size Fits All)’ 접근 방식은 응답 지연 시간(Latency) 목표 달성을 어렵게 만들고 비용을 크게 증가시킵니다. 즉각적인 해결책: 바로 vLLM Semantic Router입니다. 애플리케이션 코드에서 실행되는 파이썬 기반 라우팅 라이브러리와 달리, 이는 고성능 인프라 레이어입니다(Rust 및 Go로 작성됨). 이는 추론 엔진 이전 단계에서 지능형 게이트웨이 역할을 하며, 요청의 특정 의도를 처리할 수 있는 가장 저렴한 모델로 요청을 라우팅하고, 보안을 강화하며, 의미론적으로 동일한 쿼리를 캐싱합니다.
핵심 개념: MoM(Mixture-of-Models) 게이트웨이
vLLM Semantic Router는 MoM(Mixture-of-Models) 아키텍처를 도입합니다. 하나의 모델이 모든 것을 처리하는 대신, 라우터는 경량 BERT 기반 분류기(Hugging Face Candle에서 실행)를 사용하여 들어오는 프롬프트를 동적으로 분류합니다.
- 의도 분류 (Intent Classification): 쿼리가 “수학”, “코딩”, “일반 채팅” 또는 “악의적”인지 판단합니다.
- 의미론적 캐싱 (Semantic Caching): 벡터 저장소(Milvus/Redis)에서 이전에 유사한 쿼리가 있었는지 확인합니다.
- 라우팅 (Routing): 적절한 백엔드로 요청을 전달합니다(예: 채팅은 Qwen-7B, 코딩은 DeepSeek-V3).
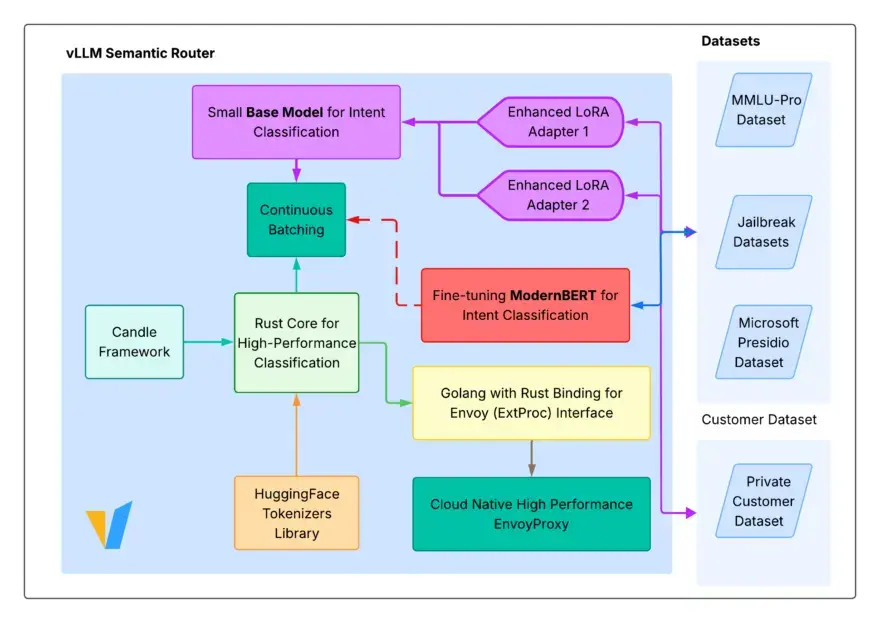
코드: 라우팅 로직 정의
vLLM Semantic Router는 서비스로 작동하므로, 여기서 말하는 “코드”는 모델(Models), 경로(Routes), 보안 정책(Security Policies)을 정의하는 선언적 구성 파일입니다. 아래는 “추론 예산(Reasoning Budget)” 전략을 구현하는 운영 환경에 바로 적용 가능한 config.yaml 파일입니다.
# config.yaml
version: "v1"
# 1. 추론 백엔드 정의 ("전문가들")
backends:
- name: "fast-chat"
type: "openai"
url: "http://vllm-small:8000/v1"
model: "Qwen/Qwen2.5-7B-Instruct"
- name: "heavy-reasoner"
type: "openai"
url: "http://vllm-large:8000/v1"
model: "deepseek-ai/DeepSeek-V3"
# 2. 라우터 로직 정의
router:
mode: "semantic" # 임베딩 기반 분류 사용
embedding_model: "sentence-transformers/all-MiniLM-L6-v2"
routes:
# 경로 1: 잡담을 위한 저렴한 모델
- name: "chitchat"
backend: "fast-chat"
samples:
- "안녕하세요, 잘 지내시나요?"
- "재미있는 농담 하나 해주세요."
- "오늘 날씨는 어떤가요?"
# 경로 2: 코딩/수학을 위한 비싼 모델
- name: "complex-tasks"
backend: "heavy-reasoner"
samples:
- "이 JSON을 파싱하는 파이썬 스크립트를 작성해 주세요."
- "트랜스포머 어텐션 메커니즘의 유도를 설명해 주세요."
- "이 세그먼트 오류 추적(segfault trace)을 디버깅해 주세요."
# 3. 보안 및 캐싱 레이어
middleware:
sem_cache:
enabled: true
backend: "redis" # 또는 'milvus'
ttl: 3600
similarity_threshold: 0.95
guardrails:
jailbreak_detection: true
pii_masking: true
단계별 구현 가이드
이 가이드는 Docker와 GPU가 장착된 머신이 준비되었다고 가정합니다. 라우터와 두 개의 vLLM 인스턴스를 함께 배포합니다.
1. 인프라 저장소 복제
이 특정 저장소에는 vLLM에 최적화된 Rust/Go 라우터 구현이 포함되어 있습니다.
git clone [https://github.com/vllm-project/semantic-router.git](https://github.com/vllm-project/semantic-router.git)
cd semantic-router
2. 라우터 구성
config.yaml 파일을 생성하고(위 코드 사용), ./config 디렉토리에 저장합니다. 백엔드 URL이 내부 Docker DNS 또는 IP 주소와 일치하는지 확인하십시오.
3. 스택 실행 (Docker Compose)
제공된 퀵스타트 스크립트 또는 compose 파일을 사용합니다. 이는 라우터, 임베딩 모델 서버 및 캐시를 실행합니다.
# Rust에 최적화된 내부 구조를 가진 공식 Docker 이미지를 사용합니다.
docker-compose -f docker-compose.yml up -d
4. 라우팅 동작 확인
요청은 vLLM 인스턴스가 아닌 라우터 포트(8080이 일반적)로 전송해야 합니다.
“Fast” 경로 테스트:
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "router-gateway",
"messages": [{"role": "user", "content": "재미있는 농담 하나 해줘"}]
}'
# 로그에 표시: Routed to [fast-chat] | Latency: 12ms
“Reasoning” 경로 테스트:
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "router-gateway",
"messages": [{"role": "user", "content": "레드-블랙 트리를 Rust로 구현해 줘."}]
}'
# 로그에 표시: Routed to [heavy-reasoner]
5. 운영 환경 기능 활성화
Kubernetes 배포의 경우, 공식 Helm Chart를 사용하십시오. 라우터는 Envoy External Processor로 기본 통합되어 밀리초 미만의 라우팅 오버헤드로 수천 개의 동시 요청을 처리할 수 있습니다.
vLLM Semantic Router는 로직을 취약한 애플리케이션 코드 밖으로 옮겨 인프라 내에 위치시킵니다. MoM 게이트웨이를 구현함으로써 “지능”과 “실행”을 효과적으로 분리하고, 모든 API 호출에서 지연 시간 비용을 지불하지 않고도 추론 능력(DeepSeek/Llama-70B)을 확장할 수 있게 됩니다.