
Technical Bottleneck: You are burning through your inference budget. Every query—whether it’s “What is 2+2?” or a complex RAG synthesis—hits your most expensive model (e.g., DeepSeek-V3 or GPT-5.2). This “One Size Fits All” approach destroys latency targets and inflates costs.
The Immediate Solution: The vLLM Semantic Router.
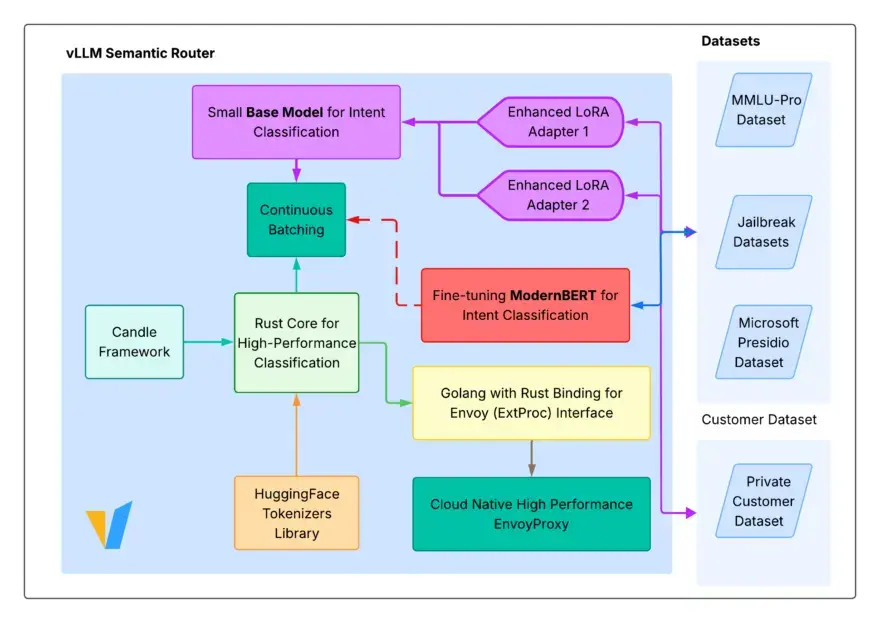
Unlike Python-based routing libraries that run in your application code, this is a high-performance infrastructure layer (written in Rust and Go). It acts as an intelligent gateway before your inference engine, routing requests to the cheapest model capable of handling the specific intent, enforcing security, and caching semantically identical queries.
Core Concept: The “Mixture-of-Models” (MoM) Gateway
The vLLM Semantic Router introduces a Mixture-of-Models (MoM) architecture. Instead of a single model doing everything, the router dynamically classifies incoming prompts using a lightweight BERT-based classifier (running on Hugging Face Candle).
- Intent Classification: Determines if the query is “Math”, “Coding”, “General Chat”, or “Malicious”.
- Semantic Caching: Checks a vector store (Milvus/Redis) for similar previous queries.
- Routing: Dispatches to the appropriate backend (e.g., Qwen-7B for chat, DeepSeek-V3 for coding).
The Code: Defining Routing Logic
Since the vLLM Semantic Router operates as a service, your “code” is the declarative configuration that defines your Models, Routes, and Security Policies.
Below is a production-ready config.yaml that implements a “Reasoning Budget” strategy:
# config.yaml
version: "v1"
# 1. Define your Inference Backends (The "Experts")
backends:
- name: "fast-chat"
type: "openai"
url: "http://vllm-small:8000/v1"
model: "Qwen/Qwen2.5-7B-Instruct"
- name: "heavy-reasoner"
type: "openai"
url: "http://vllm-large:8000/v1"
model: "deepseek-ai/DeepSeek-V3"
# 2. Define the Router Logic
router:
mode: "semantic" # Uses embedding-based classification
embedding_model: "sentence-transformers/all-MiniLM-L6-v2"
routes:
# Route 1: Cheap model for chit-chat
- name: "chitchat"
backend: "fast-chat"
samples:
- "Hi, how are you?"
- "Tell me a joke."
- "What is the weather?"
# Route 2: Expensive model for coding/math
- name: "complex-tasks"
backend: "heavy-reasoner"
samples:
- "Write a Python script to parse this JSON."
- "Explain the derivation of the transformer attention mechanism."
- "Debug this segfault trace."
# 3. Security & Caching Layers
middleware:
sem_cache:
enabled: true
backend: "redis" # or 'milvus'
ttl: 3600
similarity_threshold: 0.95
guardrails:
jailbreak_detection: true
pii_masking: true
Step-by-Step Implementation
This guide assumes you have Docker and a GPU-enabled machine. We will deploy the router alongside two vLLM instances.
1. Clone the Infrastructure Repository
This specific repository contains the Rust/Go router implementation optimized for vLLM.
git clone https://github.com/vllm-project/semantic-router.git
cd semantic-router
2. Configure the Router
Create the config.yaml file (use the snippet above) in a ./config directory. Ensure your backend URLs match your internal Docker DNS or IP addresses.
3. Launch the Stack (Docker Compose)
Use the provided quickstart script or compose file. This spins up the Router, the Embedding Model server, and the Cache.
# Uses the official Docker image with Rust-optimized internals
docker-compose -f docker-compose.yml up -d
4. Verify Routing Behavior
Send requests to the Router’s port (usually 8080), not the vLLM instances directly.
Test the “Fast” Route:
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "router-gateway",
"messages": [{"role": "user", "content": "Tell me a joke"}]
}'
# Logs should show: Routed to [fast-chat] | Latency: 12ms
Test the “Reasoning” Route:
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "router-gateway",
"messages": [{"role": "user", "content": "Write a Rust implementation of a Red-Black tree."}]
}'
# Logs should show: Routed to [heavy-reasoner]
5. Enable Production Features
For Kubernetes deployments, use the Official Helm Charts. The router integrates natively as an Envoy External Processor, allowing it to handle thousands of concurrent requests with sub-millisecond routing overhead.
The vLLM Semantic Router moves logic out of your fragile application code and into the infrastructure. By implementing a Mixture-of-Models gateway, you effectively decouple “intelligence” from “execution,” allowing you to scale up reasoning capabilities (DeepSeek/Llama-70B) without paying the latency tax on every single API call.