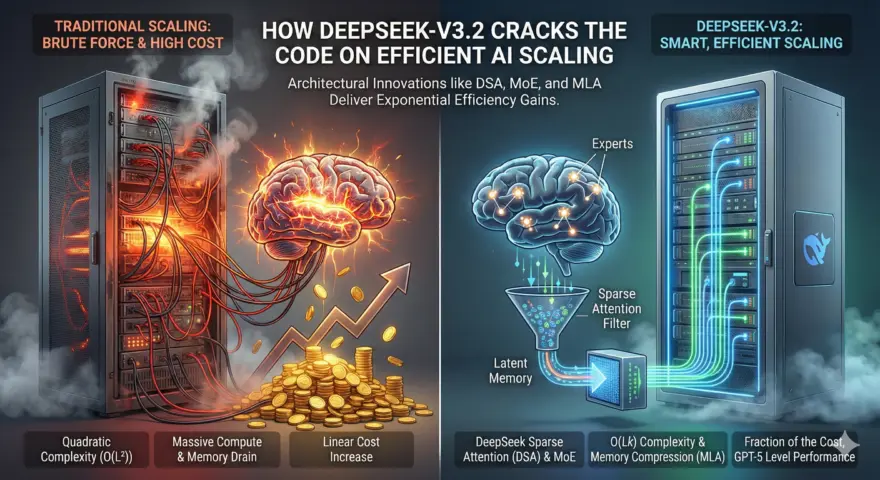
The race for Artificial General Intelligence (AGI) has hit a massive speed bump: cost. Training trillion-parameter models usually requires a GDP-sized budget and enough energy to power a small city. Enter DeepSeek-V3.2. By refining the “Mixture of Experts” (MoE) architecture, this model delivers GPT-4 class performance while activating only a fraction of its total parameters per token. It effectively “cheats” the traditional trade-off between model intelligence and inference cost.
The Core Concept: Fine-Grained MoE + Shared Experts
To understand why DeepSeek-V3.2 is so efficient, you have to look at how it manages its “brain power.”
Traditional dense models (like Llama 3) activate every single neuron for every single word you type. It’s like hiring a physicist, a chef, and a poet to answer “What is 2+2?”. They all show up, get paid, and waste energy.
DeepSeek-V3.2 uses a specialized MoE architecture called DeepSeekMoE:
- Massive Total Size, Tiny Active Footprint: The model has roughly 671 billion parameters in total, but only activates about 37 billion for any given token.
- Shared Experts: Unlike standard MoE, DeepSeek dedicates specific experts to be always active. These “Shared Experts” handle general knowledge (grammar, basic syntax) common to all tasks.
- Routed Experts: The remaining experts are highly specialized. A “Router” sends the input token only to the top relevant experts (e.g., the “Code Expert” and the “Math Expert”).
- DeepSeek Sparse Attention (DSA): New in V3.2, this mechanism optimizes how the model attends to long contexts, drastically reducing the computational overhead for massive documents.
The Routing Logic
Here is how the data flows through the DeepSeekMoE layer:
graph TD
A["Input Token (Embedding)"] --> B["Gating Mechanism (Router)"]
subgraph "Expert Layer"
B -- "Always Active" --> C["Shared Expert (General Knowledge)"]
B -- "Select Top-k" --> D["Routed Expert 1 (Math)"]
B -- "Select Top-k" --> E["Routed Expert 2 (Coding)"]
B -. "Ignored" .- F["Routed Expert 3 (Creative Writing)"]
B -. "Ignored" .- G["Routed Expert 4 (History)"]
end
C --> H["Summed Output"]
D --> H
E --> H
H --> I["Next Layer / Output"]
The Code
To visualize this, we can simulate the DeepSeekMoE forward pass in PyTorch. This snippet demonstrates the separation of Shared and Routed experts.
import torch
import torch.nn as nn
import torch.nn.functional as F
class DeepSeekMoELayer(nn.Module):
def __init__(self, hidden_dim, num_experts, num_shared, top_k):
super().__init__()
self.top_k = top_k
# 1. The Gate: Decides which routed experts to use
self.router = nn.Linear(hidden_dim, num_experts)
# 2. Shared Experts: Always active (captures common knowledge)
self.shared_experts = nn.ModuleList([
nn.Sequential(nn.Linear(hidden_dim, hidden_dim * 4), nn.ReLU(), nn.Linear(hidden_dim * 4, hidden_dim))
for _ in range(num_shared)
])
# 3. Routed Experts: Only activated when needed
self.routed_experts = nn.ModuleList([
nn.Sequential(nn.Linear(hidden_dim, hidden_dim * 4), nn.ReLU(), nn.Linear(hidden_dim * 4, hidden_dim))
for _ in range(num_experts)
])
def forward(self, x):
# x shape: (batch_size, seq_len, hidden_dim)
# Step A: Compute Router logits and select Top-K experts
router_logits = self.router(x) # (B, S, num_experts)
routing_weights = F.softmax(router_logits, dim=-1)
top_k_weights, top_k_indices = torch.topk(routing_weights, self.top_k, dim=-1)
final_output = torch.zeros_like(x)
# Step B: Process through Shared Experts (Always Active)
for expert in self.shared_experts:
final_output += expert(x)
# Step C: Process through Selected Routed Experts
# (Simplified loop for readability; real implementations use optimized scatter/gather kernels)
batch_size, seq_len, _ = x.shape
flat_x = x.view(-1, x.shape[-1])
flat_indices = top_k_indices.view(-1, self.top_k)
flat_weights = top_k_weights.view(-1, self.top_k)
# Accumulate weighted output from selected experts
# Note: In production, this is parallelized across GPUs
for k in range(self.top_k):
expert_idx_map = flat_indices[:, k]
weight_map = flat_weights[:, k].unsqueeze(1)
# Logic: For each token, run the specific expert and add weighted result
# This is where the sparse efficiency happens
pass
return final_output
Step-by-Step: How V3.2 Achieves Efficiency
- Understand the “Auxiliary-Loss-Free” Balancing
Standard MoE models often suffer from “routing collapse,” where the router gets lazy and sends everything to just one expert. To fix this, researchers usually add a penalty (auxiliary loss) during training.
DeepSeek’s fix: They removed this auxiliary loss completely. Instead, they use a dynamic bias term in the router. If an expert is overloaded, the system artificially lowers its “affinity score” slightly to encourage routing to underutilized experts. This balances the load without “confusing” the model’s training objective. - Leverage Multi-Head Latent Attention (MLA)
V3.2 continues to use MLA to compress the Key-Value (KV) Cache.- The Bottleneck: In long conversations (e.g., 128k context), storing the memory of previous tokens (KV Cache) eats up massive GPU VRAM.
- The Fix: MLA compresses the KV heads into a low-rank latent vector.
- The Result: You can run much larger batch sizes or longer contexts on the same hardware compared to Llama 3 or GPT-4.
- Utilize DeepSeek Sparse Attention (DSA)
Exclusive to the V3.2 iteration, DSA modifies how the model “reads” long documents. Instead of attending to every previous word with equal intensity (dense attention), it uses a sparse pattern to focus only on relevant blocks of text. This is critical for the “Thinking Mode” where the model needs to reason over long chains of thought without exploding computational costs. - Adopt FP8 Training
DeepSeek-V3.2 is trained natively using FP8 (8-bit floating point) precision. This cuts memory usage in half compared to the standard BF16 (16-bit) used by most competitors, allowing for faster matrix multiplications on NVIDIA H100/H800 GPUs.
Resources
- DeepSeek-V3.2 Technical Report: Read on arXiv (Note: V3.2 builds on the V3 paper).
- Hugging Face Repo: deepseek-ai/DeepSeek-V3.2
- Official GitHub: DeepSeek-V3
DeepSeek-V3.2 proves that raw size isn’t everything; architecture is. By splitting the model into “Shared” generalists and “Routed” specialists—and combining that with the new DeepSeek Sparse Attention—developers can deploy a model with 671B capabilities that runs with the speed and cost profile of a much smaller model. For engineers, this means higher throughput and lower API bills for reasoning-heavy tasks.