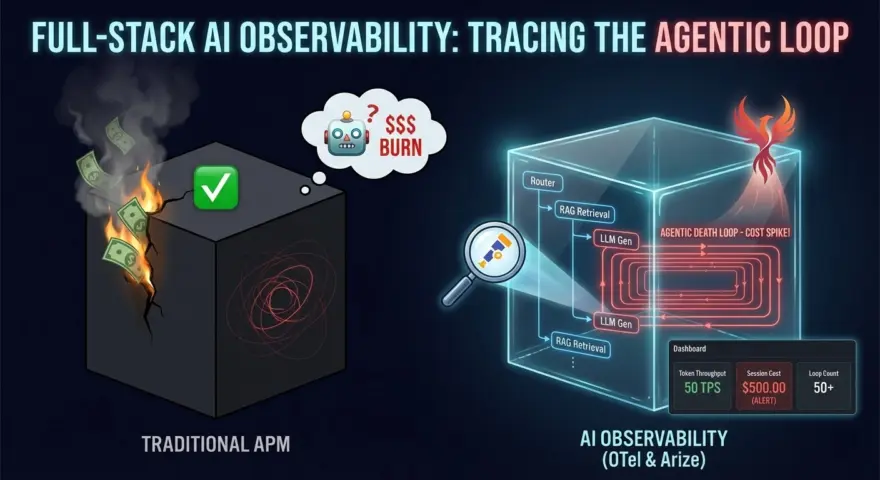
2026년 가장 비싼 버그는 메모리 누수가 아닙니다. 바로 추론 루프(Reasoning Loop)입니다.
이 시나리오를 상상해 보세요: “지원 에이전트”를 프로덕션에 배포합니다. 그 목표는 사용자의 비밀번호를 재설정하는 것입니다. 예상치 못한 API 오류가 발생합니다. 우아하게 실패하는 대신, LLM이 “다른 매개변수로 재시도”하기로 결정합니다. 재시도합니다. 또 재시도합니다. 계속 재시도합니다.
API가 200 OK를 반환하기 때문에(본문에 오류 메시지 포함), 기존 APM 도구(Datadog, New Relic)는 녹색 불을 표시합니다.
한편, 에이전트는 초당 50토큰을 소모하며 회전하고 있습니다. 10분 후 대시보드를 확인할 때쯤이면, 그 단일 세션이 GPT-5 컴퓨팅 크레딧으로 $500를 소진한 상태입니다.
에이전트 시대에 CPU 메트릭은 무관합니다. 인지적 관찰 가능성(Cognitive Observability)이 필요합니다. HTTP 요청뿐만 아니라 사고 과정을 추적해야 합니다.
이 가이드는 OpenTelemetry (OTel)과 Arize Phoenix를 사용하여 좀비 에이전트가 당신을 파산시키기 전에 탐지, 진단 및 종료하는 방법을 위한 풀스택 AI 관찰 가능성을 구현하는 방법을 상세히 설명합니다.
맹점: 표준 APM이 실패하는 이유
기존 추적(Jaeger, Zipkin)은 결정론적 마이크로서비스를 위해 구축되었습니다. 서비스 A가 서비스 B를 호출합니다.
에이전트는 비결정론적 루프입니다.
- 스팬 문제: 에이전트의 “실행”은 단일 요청이 아닙니다. 50개 이상의 LLM 호출, 도구 실행, 벡터 검색으로 구성된 그래프입니다.
- 페이로드 문제: 호출이 발생했다는 사실만 아는 것은 쓸모가 없습니다. 에이전트가 무엇을 생각하고 있었는지 알아야 합니다. 도구 매개변수를 환각했나요? 관찰 결과를 오해했나요?
- 비용 문제: 마이크로서비스에서는 비용이 고정되어 있습니다(서버 시간). AI에서는 비용이 가변적입니다(토큰 수). 1센트의 일부라도 특정 테넌트 ID나 사용자 ID에 귀속시켜야 합니다.
아키텍처: OpenInference & OTel
바퀴를 다시 발명할 필요는 없습니다. OpenTelemetry를 사용하지만, OpenInference 의미 체계 규칙을 채택합니다. 이는 2026년 LLM 애플리케이션 추적을 위한 표준입니다.
스택
- 계측: Python OpenTelemetry SDK +
openinference-instrumentation-langchain. - 수집기: OTel 수집기(사이드카로 실행).
- 백엔드: Arize Phoenix(추적 시각화 및 평가용) 또는 Grafana Tempo(장기 저장용).
청사진: 10가지 엘리트 구성 및 코드 스니펫
아래는 LangGraph 에이전트를 계측하기 위한 프로덕션 준비 구성입니다. 이 설정은 입력, 출력, 도구 호출 및 무엇보다도 단계별 토큰 비용을 캡처합니다.
1. OTel 추적기 공급자 설정 (기초)
글로벌 추적기를 구성하여 데이터를 Arize(로컬 또는 클라우드)로 내보냅니다.
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from openinference.instrumentation.langchain import LangChainInstrumentor
# 1. 추적기 공급자 초기화
tracer_provider = TracerProvider()
trace.set_tracer_provider(tracer_provider)
# 2. 내보내기 구성 (Arize Phoenix 로컬 인스턴스 대상)
otlp_exporter = OTLPSpanExporter(endpoint="http://localhost:4317", insecure=True)
span_processor = BatchSpanProcessor(otlp_exporter)
tracer_provider.add_span_processor(span_processor)
# 3. LangChain / LangGraph 자동 계측
# 이는 모든 "노드" 실행을 스팬으로 마법처럼 캡처합니다.
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
2. “테넌트 인식” 컨텍스트 전파
비용 귀속을 위해 특정 사용자 ID 또는 테넌트 ID로 추적에 태그를 지정하는 방법.
from opentelemetry import trace
tracer = trace.get_tracer(__name__)
def run_agent_for_user(user_query: str, tenant_id: str, user_id: str):
# 전체 상호작용에 대한 루트 스팬 시작
with tracer.start_as_current_span("agent_execution") as span:
# 모든 하위 스팬(LLM 호출, DB 조회)에 계단식으로 전파될 속성 설정
span.set_attribute("user.id", user_id)
span.set_attribute("tenant.id", tenant_id)
span.set_attribute("project.environment", "production")
# 이제 LangGraph 에이전트 호출
# 계측기가 자동으로 이러한 속성을 LLM 호출에 첨부합니다.
agent_graph.invoke({"messages": [user_query]})
3. “토큰 누출” 탐지기 (비용 추적)
모델 이름을 기반으로 실시간 비용을 계산하는 사용자 정의 스팬 프로세서.
# 비용 프로세서 로직을 위한 의사 코드
MODEL_COSTS = {
"gpt-4o-2024-05-13": {"input": 5.00, "output": 15.00}, # 100만 토큰당 $
"claude-3-5-sonnet": {"input": 3.00, "output": 15.00}
}
def calculate_cost(span):
model = span.attributes.get("llm.model_name")
input_tokens = span.attributes.get("llm.token_count.prompt")
output_tokens = span.attributes.get("llm.token_count.completion")
if model in MODEL_COSTS:
cost = (input_tokens / 1e6 * MODEL_COSTS[model]['input']) +
(output_tokens / 1e6 * MODEL_COSTS[model]['output'])
span.set_attribute("llm.cost.usd", cost)
4. “무한 루프” 회로 차단기
루프를 단지 관찰하지 말고, 종료하세요. 이 로직은 추적 깊이를 확인합니다.
# LangGraph 노드 내부
def reasoning_node(state):
# 상태에서 재귀 깊이 확인
current_depth = len(state['messages'])
if current_depth > 20:
# 긴급 정지
# OTel에 "중요 이벤트" 스팬 기록
with tracer.start_as_current_span("emergency_halt") as span:
span.set_attribute("error", True)
span.set_attribute("reason", "최대 재귀 깊이 초과")
return {"messages": [SystemMessage(content="오류: 에이전트가 루프에 갇혔습니다. 종료합니다.")]}
# 정상 로직 계속...
5. 추적에서 PII 마스킹 (GDPR 준수)
PII를 포함하는 경우 원시 프롬프트를 기록하지 마세요. 앱을 떠나기 전에 민감한 데이터를 삭제하기 위해 사용자 정의 훅을 사용하세요.
from openinference.instrumentation import SafeLogger
class PIIRedactor:
def redact(self, text):
# 이메일, 주민등록번호, 신용카드에 대한 정규식
return re.sub(r'b[w.-]+@[w.-]+.w{2,4}b', '[이메일_삭제됨]', text)
# 삭제기를 사용하도록 계측기 구성
LangChainInstrumentor().instrument(
tracer_provider=tracer_provider,
response_hook=lambda span, response: span.set_attribute("output", PIIRedactor().redact(response))
)
6. 도구 실행 추적 (The “Action” Layer)
에이전트가 API에 전달한 정확한 인수를 시각화하세요.
# 도구가 추적 시각화에 표시되도록 데코레이트
from langchain.tools import tool
@tool
def query_sql_database(query: str):
"""SQL 쿼리를 실행합니다."""
# 'tool' 데코레이터 + OTel 자동 계측이 다음을 캡처합니다:
# 1. 입력 'query'
# 2. 실행 시간
# 3. 결과 행(또는 오류)
return db.run(query)
7. “환각률” 메트릭
Arize의 평가 라이브러리를 사용하여 추적을 비동기적으로 등급 매기세요.
from phoenix.evals import HallucinationEvaluator, run_evals
import pandas as pd
# 지난 1시간 동안의 추적 가져오기
dataframe = phoenix_client.get_spans_dataframe(filter="span_kind == 'LLM'")
# 환각 평가기 실행 (작은 LLM을 사용하여 큰 LLM을 판단)
eval_results = run_evals(
evaluators=[HallucinationEvaluator(model="gpt-4-turbo")],
dataframe=dataframe,
provide_explanation=True
)
# 환각률이 10%를 초과하면 PagerDuty 트리거
if eval_results['hallucination_score'].mean() > 0.1:
alert_devops_team()
8. 분산 추적 ID 주입 (메타 프롬프팅)
시스템 프롬프트에 추적 ID를 주입하여 LLM이 자체 디버그 ID를 “알게” 하세요.
trace_id = trace.get_current_span().get_span_context().trace_id
system_prompt = f"""
당신은 도움이 되는 어시스턴트입니다.
디버그_추적_ID: {trace_id}
치명적인 오류가 발생하면 이 추적 ID를 사용자에게 출력하세요.
"""
9. 단계 유형별 지연 시간 버킷팅
“사고 시간”(LLM 생성)과 “행동 시간”(도구 지연 시간)을 구분하세요.
# Arize / Prometheus 쿼리
sum(rate(span_duration_seconds_sum{span_kind="LLM"}[5m]))
vs
sum(rate(span_duration_seconds_sum{span_kind="TOOL"}[5m]))
# 통찰: 도구 지연 시간이 급증하면 DB 문제입니다. LLM 지연 시간이 급증하면 OpenAI 문제입니다.
10. 추적 샘플링 정책
프로덕션에서 모든 것을 추적하지 마세요. 속도가 느려집니다.
# 헤드 기반 샘플링 구성
from opentelemetry.sdk.trace.sampling import ParentBased, TraceIdRatioBased
# 요청의 10%를 추적하지만, 오류가 있는 요청은 항상 추적
sampler = ParentBased(root=TraceIdRatioBased(0.1))
tracer_provider = TracerProvider(sampler=sampler)
2026년 구현을 위한 모범 사례
1. AI의 “황금 신호”
CPU/RAM은 잊으세요. 대시보드에 표시해야 할 내용:
- 토큰 처리량 (TPS): 초당 토큰 수.
- 세션당 비용: 가장 중요한 비즈니스 메트릭.
- 루프 횟수: 세션당 평균 턴 수. 이 수치가 급증하면 프롬프트가 고장난 것입니다.
- 피드백 점수: 특정 추적 ID에 연결된 사용자 / 비율.
2. 프로덕션 문자열에서 디버깅하지 마세요
print(response) 사용을 중지하세요. 확장 불가능하고 안전하지 않습니다. Arize의 추적 폭포 보기를 사용하세요. 이를 통해 단일 채팅 세션을 확장하고 정확한 순서를 볼 수 있습니다:
사용자 쿼리 -> 라우터 -> RAG 검색 -> 컨텍스트 스터핑 -> LLM 생성 -> 도구 호출 -> 최종 답변.
3. “비용 속도”에 대해 경고 설정
경고를 설정하세요: “단일 추적 ID가 $2.00 이상 소비하면 연결을 종료하세요.”
이것은 재귀 루프 버그가 하룻밤 사이에 당신의 지갑을 고갈시키는 것에 대한 보험 정책입니다.
“블랙박스”에서 “글래스박스”로
추적할 수 없다면, 신뢰할 수 없습니다.
OTel 없이 자율 에이전트를 구축하는 것은 창문이 검게 칠해진 비행기를 조종하는 것과 같습니다. 빠르게 움직이고 있을 수 있지만, 목적지로 가고 있는지 산으로 가고 있는지 전혀 알 수 없습니다.
오늘 arize-phoenix를 로컬에 설치하세요 (pip install arize-phoenix). 개발 머신에서 추적 공급자 설정 (구성 #1)을 실행하세요. 에이전트의 “사고 과정”이 타임라인으로 시각화되는 것을 처음 보는 것은 계시와 같습니다.