2026年最昂贵的漏洞不是内存泄漏,而是推理循环。
想象这个场景:你将一个“支持助手”部署到生产环境。它的目标是重置用户密码。它遇到了意外的API错误。LLM没有优雅地失败,而是决定“用不同参数重试”。它重试了。又重试了。再重试了。
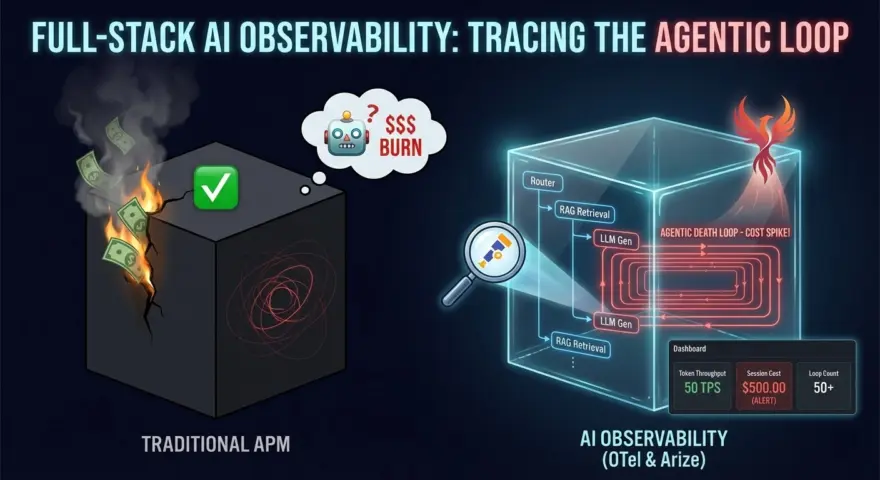
由于API返回200 OK(响应体中包含错误信息),你的传统APM工具(Datadog、New Relic)显示绿灯。
与此同时,你的智能体正以每秒50个令牌的速度空转。等你10分钟后查看仪表板时,单次会话已消耗了500美元的GPT-5计算额度。
在智能体时代,CPU指标已无关紧要。你需要认知可观测性。你需要追踪思考过程,而不仅仅是HTTP请求。
本指南详细介绍了如何使用OpenTelemetry (OTel)和Arize Phoenix实现全栈AI可观测性,以便在僵尸智能体让你破产之前检测、诊断并终止它们。
盲点:为何标准APM会失效
传统追踪系统(Jaeger、Zipkin)是为确定性微服务构建的。服务A调用服务B。
智能体是非确定性循环。
- 跨度问题:智能体的单次“运行”不是单个请求;而是包含50多次LLM调用、工具执行和向量搜索的图。
- 载荷问题:仅仅知道发生了调用毫无用处。你需要知道智能体当时在想什么。它是否幻觉出了工具参数?是否误解了观察结果?
- 成本问题:在微服务中,成本是固定的(服务器时间)。在AI中,成本是可变的(令牌数量)。你需要将每一分钱的成本归因到特定的租户ID或用户ID。
架构:OpenInference与OTel
我们无需重复造轮子。我们使用OpenTelemetry,但采用OpenInference语义约定——这是2026年追踪LLM应用的标准。
技术栈
- 插桩:Python OpenTelemetry SDK +
openinference-instrumentation-langchain。 - 收集器:OTel收集器(以边车模式运行)。
- 后端:Arize Phoenix(用于追踪可视化和评估)或Grafana Tempo(用于长期存储)。
蓝图:10个精英配置与代码片段
以下是用于插桩LangGraph智能体的生产就绪配置。此设置捕获输入、输出、工具调用,以及至关重要的——每一步的令牌成本。
1. OTel追踪器提供程序设置(基础)
配置全局追踪器,将数据导出到Arize(本地或云端)。
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from openinference.instrumentation.langchain import LangChainInstrumentor
# 1. 初始化追踪器提供程序
tracer_provider = TracerProvider()
trace.set_tracer_provider(tracer_provider)
# 2. 配置导出器(指向Arize Phoenix本地实例)
otlp_exporter = OTLPSpanExporter(endpoint="http://localhost:4317", insecure=True)
span_processor = BatchSpanProcessor(otlp_exporter)
tracer_provider.add_span_processor(span_processor)
# 3. 自动插桩LangChain / LangGraph
# 这将神奇地捕获每次“节点”执行作为一个跨度
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
2. “租户感知”的上下文传播
如何用特定的用户ID或租户ID标记追踪,以便进行成本归因。
from opentelemetry import trace
tracer = trace.get_tracer(__name__)
def run_agent_for_user(user_query: str, tenant_id: str, user_id: str):
# 为整个交互启动一个根跨度
with tracer.start_as_current_span("agent_execution") as span:
# 设置将级联到所有子跨度(LLM调用、数据库查询)的属性
span.set_attribute("user.id", user_id)
span.set_attribute("tenant.id", tenant_id)
span.set_attribute("project.environment", "production")
# 现在调用你的LangGraph智能体
# 插桩器会自动将这些属性附加到LLM调用上
agent_graph.invoke({"messages": [user_query]})
3. “令牌消耗”检测器(成本追踪)
一个基于模型名称实时计算成本的自定义跨度处理器。
# 成本处理器逻辑的伪代码
MODEL_COSTS = {
"gpt-4o-2024-05-13": {"input": 5.00, "output": 15.00}, # 每百万令牌美元价格
"claude-3-5-sonnet": {"input": 3.00, "output": 15.00}
}
def calculate_cost(span):
model = span.attributes.get("llm.model_name")
input_tokens = span.attributes.get("llm.token_count.prompt")
output_tokens = span.attributes.get("llm.token_count.completion")
if model in MODEL_COSTS:
cost = (input_tokens / 1e6 * MODEL_COSTS[model]['input']) +
(output_tokens / 1e6 * MODEL_COSTS[model]['output'])
span.set_attribute("llm.cost.usd", cost)
4. “无限循环”断路器
不要仅仅观察循环;要终止它。此逻辑检查追踪深度。
# 在你的LangGraph节点内部
def reasoning_node(state):
# 从状态中检查递归深度
current_depth = len(state['messages'])
if current_depth > 20:
# 紧急停止
# 向OTel记录一个“关键事件”跨度
with tracer.start_as_current_span("emergency_halt") as span:
span.set_attribute("error", True)
span.set_attribute("reason", "超出最大递归深度")
return {"messages": [SystemMessage(content="错误:智能体陷入循环。正在终止。")]}
# 继续正常逻辑...
5. 在追踪中屏蔽PII(GDPR合规)
如果原始提示包含PII,切勿记录。使用自定义钩子在数据离开应用前擦除敏感数据。
from openinference.instrumentation import SafeLogger
class PIIRedactor:
def redact(self, text):
# 用于电子邮件、社会安全号码、信用卡的正则表达式
return re.sub(r'b[w.-]+@[w.-]+.w{2,4}b', '[EMAIL_REDACTED]', text)
# 配置插桩器使用擦除器
LangChainInstrumentor().instrument(
tracer_provider=tracer_provider,
response_hook=lambda span, response: span.set_attribute("output", PIIRedactor().redact(response))
)
6. 追踪工具执行(“行动”层)
可视化智能体传递给API的确切参数。
# 装饰你的工具,确保它们出现在追踪可视化中
from langchain.tools import tool
@tool
def query_sql_database(query: str):
"""执行SQL查询。"""
# 'tool'装饰器 + OTel自动插桩捕获:
# 1. 输入'query'
# 2. 执行时间
# 3. 结果行(或错误)
return db.run(query)
7. “幻觉率”指标
使用Arize的评估库异步评估追踪。
from phoenix.evals import HallucinationEvaluator, run_evals
import pandas as pd
# 拉取过去一小时的追踪
dataframe = phoenix_client.get_spans_dataframe(filter="span_kind == 'LLM'")
# 运行幻觉评估器(使用小型LLM来评判大型LLM)
eval_results = run_evals(
evaluators=[HallucinationEvaluator(model="gpt-4-turbo")],
dataframe=dataframe,
provide_explanation=True
)
# 如果幻觉率 > 10%,触发PagerDuty告警
if eval_results['hallucination_score'].mean() > 0.1:
alert_devops_team()
8. 分布式追踪ID注入(元提示)
将追踪ID注入系统提示,让LLM“知道”它自己的调试ID。
trace_id = trace.get_current_span().get_span_context().trace_id
system_prompt = f"""
你是一个乐于助人的助手。
DEBUG_TRACE_ID: {trace_id}
如果遇到致命错误,请向用户输出此追踪ID。
"""
9. 按步骤类型进行延迟分桶
区分“思考时间”(LLM生成)和“行动时间”(工具延迟)。
# Arize / Prometheus 查询
sum(rate(span_duration_seconds_sum{span_kind="LLM"}[5m]))
vs
sum(rate(span_duration_seconds_sum{span_kind="TOOL"}[5m]))
# 洞察:如果工具延迟激增,是你的数据库问题。如果LLM延迟激增,是OpenAI的问题。
10. 追踪采样策略
不要在生成环境中追踪所有内容。这会拖慢速度。
# 配置基于头部的采样
from opentelemetry.sdk.trace.sampling import ParentBased, TraceIdRatioBased
# 追踪10%的请求,但始终追踪包含错误的请求
sampler = ParentBased(root=TraceIdRatioBased(0.1))
tracer_provider = TracerProvider(sampler=sampler)
2026年实施最佳实践
1. AI的“黄金信号”
忘掉CPU/内存。你的仪表板应显示:
- 令牌吞吐量(TPS):每秒令牌数。
- 单会话成本:最关键的业务指标。
- 循环次数:单次会话的平均轮数。如果此值激增,说明你的提示词有问题。
- 反馈评分:用户 / 比例,关联到特定的追踪ID。
2. 不要在生成环境中调试字符串
停止使用print(response)。它不可扩展且不安全。使用Arize中的追踪瀑布视图。它允许你展开单个聊天会话,并查看确切的序列:
用户查询 -> 路由器 -> RAG检索 -> 上下文填充 -> LLM生成 -> 工具调用 -> 最终答案。
3. 对“成本速度”设置告警
设置告警:“如果任何单个追踪ID消耗 > 2.00美元,则终止连接。”
这是防止递归循环漏洞一夜之间耗尽你钱包的保险策略。
从“黑盒”到“玻璃盒”
如果你无法追踪它,你就无法信任它。
在没有OTel的情况下构建自主智能体,就像驾驶一架窗户被涂黑的飞机。你可能飞得很快,但你根本不知道是飞向目的地还是撞向山峦。
今天就本地安装arize-phoenix(pip install arize-phoenix)。在你的开发机器上运行追踪提供程序设置(配置 #1)。第一次看到智能体的“思考过程”以时间线形式可视化,将是一次顿悟。