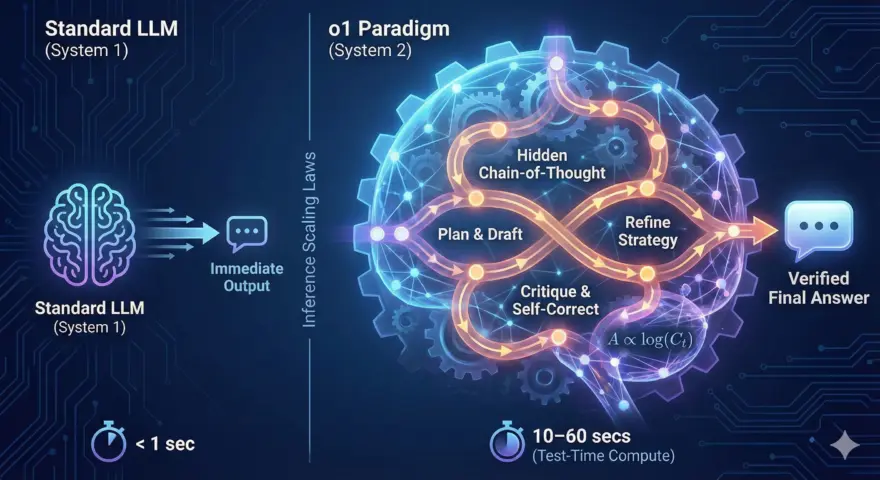
If you’ve used OpenAI’s o-series models (like o1, o3, o4), you’ve noticed something unsettling: the pause.
For years, we optimized Large Language Models (LLMs) for speed. We wanted near-instant text generation, measuring latency in milliseconds. But late 2024 marked a pivotal shift in computer science: the transition from Training-Time Compute to Inference-Time Compute.
The “o1 Paradigm” isn’t just a new model update; it is the industrialization of System 2 thinking for AI. It trades speed for intelligence, spending computational resources to “think” silently before it speaks.
Here is why this changes everything for developers and engineers, and how you must adapt your workflow.
The Core Concept: Inference-Time Compute
To understand o1, you must understand the Scaling Laws of Inference.
Previously, an AI’s intelligence was capped by how much compute was poured into its training phase (the months spent learning from the internet). Once trained, the model was static. It was a “System 1” thinker—fast, instinctive, and prone to hallucinations on complex logic.
The o1 paradigm introduces a new variable: Test-Time Compute. By allowing the model to generate “hidden tokens”—internal thoughts that users never see—the model can self-correct, plan, and backtrack during the API call.
System 1 vs. System 2
- System 1 (GPT-4o, Claude 3.5 Sonnet): “Fast thinking.” Pattern matching. Good for creative writing, simple code, and summaries.
- System 2 (o1, o3-mini, DeepSeek R1): “Slow thinking.” Deliberate reasoning. Good for architecture, complex math, and legal analysis.
The relationship between performance and compute has changed. We can now approximate the scaling law as:
This means we can achieve higher intelligence not just by training bigger models, but by letting them “think” longer.
Visualizing the Hidden Chain
The following diagram illustrates how a Reasoning Model differs from a standard LLM.
graph TD
A["User Prompt"] --> B{"Model Type"}
B -- "Standard LLM (GPT-4o)" --> C["Token Prediction"]
C --> D["Immediate Output"]
B -- "Reasoning Model (o1)" --> E["Start Hidden Chain-of-Thought"]
E --> F["Decompose Problem"]
F --> G["Draft Solution"]
G --> H{"Self-Correction Needed?"}
H -- "Yes (Error Found)" --> F
H -- "No" --> I["Synthesize Final Answer"]
I --> D
style E fill:#333,stroke:#fff,color:#fff
style F fill:#333,stroke:#fff,color:#fff
style G fill:#333,stroke:#fff,color:#fff
style H fill:#333,stroke:#fff,color:#fff
The Code: Handling Reasoning Tokens
When building with o1-class models, you are billed for Reasoning Tokens. These are the hidden tokens the model generates while thinking. They do not appear in the final response, but they consume your context window and your budget.
Here is how to structure a request using the OpenAI SDK (v1.50+), specifically handling the reasoning_effort parameter introduced to control how hard the model thinks.
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Define a complex logical task
prompt = """
Design a Python class hierarchy for a distributed task scheduler.
It must handle race conditions using optimistic locking and support
priority queues with varying distinct levels.
"""
response = client.chat.completions.create(
model="o1", # or "o3-mini"
messages=[
{"role": "user", "content": prompt}
],
# 'reasoning_effort' controls the depth of the hidden chain.
# Options: "low", "medium", "high"
reasoning_effort="high"
)
# Extracting the content
final_answer = response.choices[0].message.content
# Inspecting usage to see the "Thinking Cost"
usage = response.usage
input_tokens = usage.prompt_tokens
output_tokens = usage.completion_tokens
# 'reasoning_tokens' are a subset of completion_tokens
reasoning_tokens = usage.completion_tokens_details.reasoning_tokens
print(f"Final Answer Length: {len(final_answer)} chars")
print(f"Total Output Tokens: {output_tokens}")
print(f"Hidden Reasoning Tokens: {reasoning_tokens}")
Key Takeaway from Code:
If reasoning_tokens is 4000 and your visible output is only 200 tokens, the model spent massive compute “thinking” about the architecture before writing a single line of code.
Step-by-Step Guide: Prompting for Reasoning
Old habits die hard. The prompt engineering tricks that worked for GPT-4 (Chain-of-Thought prompting, “Take a deep breath”) are now antipatterns. They interfere with the model’s native reasoning process.
- Stop Asking for “Step-by-Step”:
Do not ask the model to “think step-by-step.” It already does this natively in the hidden chain. Forcing it to do so in the visible output degrades performance and wastes tokens. - Use “Developer” Messages, Not “System”:
For o1-preview and early o1 versions, thesystemrole was often deprecated in favor ofuserordeveloperroles to avoid constraining the reasoning capabilities. (Check current API specs as this evolves rapidly). - Prioritize Context Over Instruction:
Instead of telling the model how to think (instructions), give it more data on what to think about (context).- Bad: “Solve this logic puzzle. First list variables, then define constraints…”
- Good: “Solve this logic puzzle. Here are the variables, constraints, and the desired output format.”
- Manage the Context Window:
Reasoning tokens count toward the context limit. If your input prompt is massive (e.g., 100k tokens), the model has less “scratchpad” space to think. For complex tasks, use RAG (Retrieval-Augmented Generation) to feed only relevant snippets. - Use Delimiters:
Structure your prompts clearly. Reasoning models excel when data is compartmentalized.<policy_document> [Insert text] </policy_document> <user_query> [Insert query] </user_query>
The o1 paradigm signals the end of “vibe-based” AI and the beginning of verifiable reasoning. We are no longer just prompting for text; we are prompting for thought. Your job is no longer to guide the model’s hand, but to define the problem clearly enough that it can guide itself.
External Resources
- OpenAI Research: Learning to Reason with LLMs
- arXiv Paper: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- Documentation: OpenAI Reasoning Best Practices