Imagine reading a mystery novel, but by the time you reach page 100, you have completely forgotten who committed the murder on page 5. This is the “Goldfish Memory” problem in Large Language Models (LLMs).
For years, LLMs were shackled by fixed context windows (2k or 4k tokens). If you pasted a large PDF, the model would simply truncate the end—or hallucinate. The limitation wasn’t just memory; it was the Positional Embeddings—the mathematical GPS that tells the model the order of words.
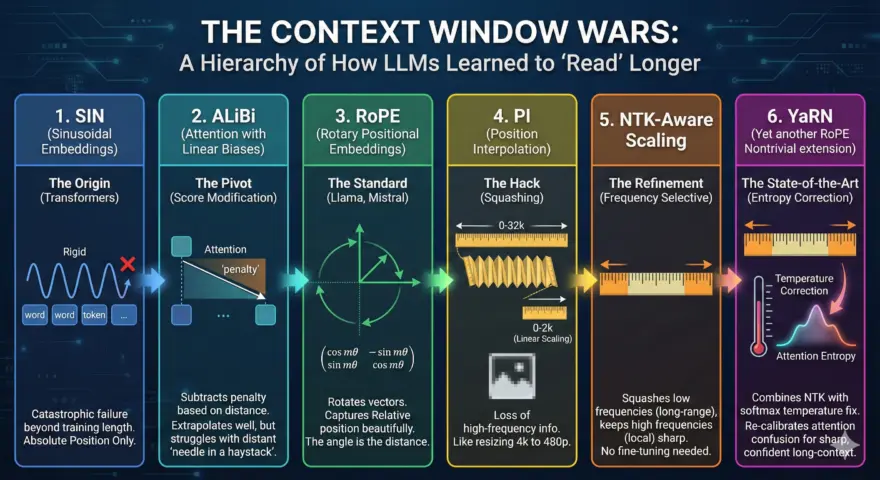
We have witnessed a rapid evolution in how models handle “space” and “time,” moving from rigid absolute positions to flexible, infinite-context scaling. Here is how we got from basic sine waves to the state-of-the-art YaRN.
The Core Concept: The “Resolution” Problem
To understand context extension, you must understand the resolution dilemma.
Old methods treated position like specific house numbers (1, 2, 3…). If you trained a model to understand 100 houses, it panicked when it saw house #101.
Newer methods (like RoPE and YaRN) treat position like a flexible rubber band. If you want to fit 200 houses into a street designed for 100, you don’t build more street; you shrink the houses (interpolation). However, if you shrink them too much, they become blurry, and the model can’t distinguish between neighbors. The goal of modern techniques is to stretch the context window without losing that fine-grained resolution.
The Evolution of Position
Here is the hierarchy of how LLMs learned to “read” longer documents.
1. SIN (Sinusoidal Embeddings)
- The Origin: Introduced in Attention Is All You Need (Transformers).
- How it works: It adds a fixed sine/cosine wave pattern to the word embeddings.
- The Flaw: It is Absolute. The model learns “Position 5” specifically, not “5 words after Position 1.” It fails catastrophically if you go beyond the training length.
2. ALiBi (Attention with Linear Biases)
- The Pivot: Instead of adding embeddings to the input, ALiBi modifies the Attention Score directly.
- How it works: It subtracts a penalty from the attention score based on how far apart two words are. The further away, the lower the attention.
- The Win: It extrapolates perfectly. You can train on 2k tokens and test on 8k.
- The Loss: It struggles with “needle in a haystack” tasks because it heavily penalizes distant tokens.
3. RoPE (Rotary Positional Embeddings)
- The Standard: Used by Llama, Mistral, and PaLM.
- How it works: It rotates the Query and Key vectors in 2D space. The angle of rotation represents the position.
- The Math:
- The Win: It captures Relative position beautifully (the angle between two vectors depends only on their distance, not their absolute position).
4. PI (Position Interpolation)
- The Hack: Researchers wanted to extend Llama 1 (2k context) to 32k.
- How it works: Instead of extrapolating to angles the model hasn’t seen, PI “squashes” the 32k positions into the 0-2k range (linear scaling).
- The Flaw: It causes a loss of high-frequency information. It’s like resizing a 4k image down to 480p—you lose the sharp edges.
5. NTK-Aware Scaling
- The Refinement: Neural Tangent Kernel (NTK) theory suggests that deep networks struggle to learn high-frequency components.
- How it works: Instead of squashing everything equally (linear PI), NTK scaling squashes low frequencies (long-range) but keeps high frequencies (local range) untouched.
- The Result: You can extend the context window without fine-tuning, and the model stays sharp on local tasks.
6. YaRN (Yet another RoPE Nontrivial extension)
- The State-of-the-Art: Used in models like Nous-Hermes and modern Llama finetunes.
- The Problem: When you interpolate RoPE, the “entropy” of the attention distribution shifts—the model gets confused about how “focused” its attention should be.
- The Fix: YaRN combines NTK scaling with a temperature correction on the attention softmax. It effectively “re-calibrates” the confusion caused by stretching the context.
The Code: Implementing YaRN Scaling
You don’t need to write the math from scratch. Most modern libraries like transformers support this configuration out of the box.
Here is how you configure a Llama model to use YaRN scaling to extend a 4k model to 128k context.
from transformers import AutoConfig, AutoModelForCausalLM
# Load the base configuration
config = AutoConfig.from_pretrained("meta-llama/Llama-2-7b-hf")
# Modify the RoPE scaling configuration for YaRN
# original_max_position_embeddings was 4096
config.rope_scaling = {
"type": "yarn", # Specify YaRN method
"factor": 32.0, # Scale factor (128k / 4k = 32)
"original_max_position_embeddings": 4096,
"finetuned": False # Set True if you are loading a model already finetuned on long context
}
# Load model with new config
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
config=config,
device_map="auto"
)
print(f"Model context window extended to: {config.max_position_embeddings * config.rope_scaling['factor']}")
Step-by-Step: Choosing Your Strategy
If you are building or fine-tuning an LLM, follow this decision matrix:
- Standard Context (< 4k): Stick to Vanilla RoPE. It is robust and supported everywhere.
- Zero-Shot Extension: If you need to take a pre-trained Llama 2/3 and instantly read a longer PDF without training, use Dynamic NTK. It works surprisingly well “out of the box.”
- Fine-Tuning for Long Context: If you have the compute to fine-tune, use YaRN. It converges faster and retains higher accuracy on the original short-context tasks compared to linear interpolation.
- Hardware Constraints: If you are memory constrained, look into ALiBi (or newer variants like Ring Attention), as they handle memory limits more gracefully during inference.
Conclusion
The jump from “Sinusoidal” to “YaRN” represents a shift from memorizing positions to understanding the relativity of information. We have moved from models that get confused after a few paragraphs to models that can digest entire novels in a single pass.
- RoPE gave us the rotation.
- PI showed us we could stretch it.
- NTK taught us to stretch smartly.
- YaRN perfected the focus.