
The Bottleneck: The “Smart vs. Fast” Deadlock
For the last two years, building production-grade AI agents forced a painful compromise. You had two choices:
- The “Pro” Route (Gemini 3 Pro / GPT-5.2 Pro): High reasoning capabilities and 80%+ SWE-bench scores, but crippling latency (2-5s+ TTFT) and prohibitive costs ($10+/1M output tokens).
- The “Flash” Route (Gemini 2.5 Flash / GPT-4o-mini): Sub-second latency and dirt-cheap inference, but frequent hallucinations in multi-step planning and tool-use failure.
This deadlock killed real-time agentic applications. You couldn’t build a reliable customer service voice bot or a live coding assistant because the “smart” models were too slow, and the “fast” models were too dumb.
Gemini 3 Flash ends this trade-off. It is the first sub-second latency model to integrate Thinking Levels, allowing you to dynamically scale reasoning depth per request without switching models.
The Architecture: Configurable “Thinking” at Edge Speed
The core breakthrough in Gemini 3 Flash is the decoupling of reasoning depth from model size. Unlike GPT-5.2, which forces you to switch model tiers (Instant vs. Thinking), Gemini 3 Flash exposes a thinking_level parameter.
This mechanism works by allocating a variable “Thought Budget” (hidden token generation) before the final response.
- Logic Flow: Input [Thought Process (Hidden)] [Final Output]
- The Difference: You control the compute spent in the hidden block.
Decision Logic for Thinking Levels
Use this decision matrix to optimize your API calls:
| Thinking Level | Use Case | Latency Target | Token Overhead |
|---|---|---|---|
MINIMAL |
Simple classification, data extraction, formatting. | < 500ms | ~0 tokens |
LOW |
RAG summarization, single-step tool calling. | ~800ms | 100-500 tokens |
MEDIUM |
Multi-step agent routing, complex SQL generation. | 1.5s | 1k-2k tokens |
HIGH |
Full autonomous coding (SWE-bench tasks), math proofs. | 3s+ | 4k+ tokens |
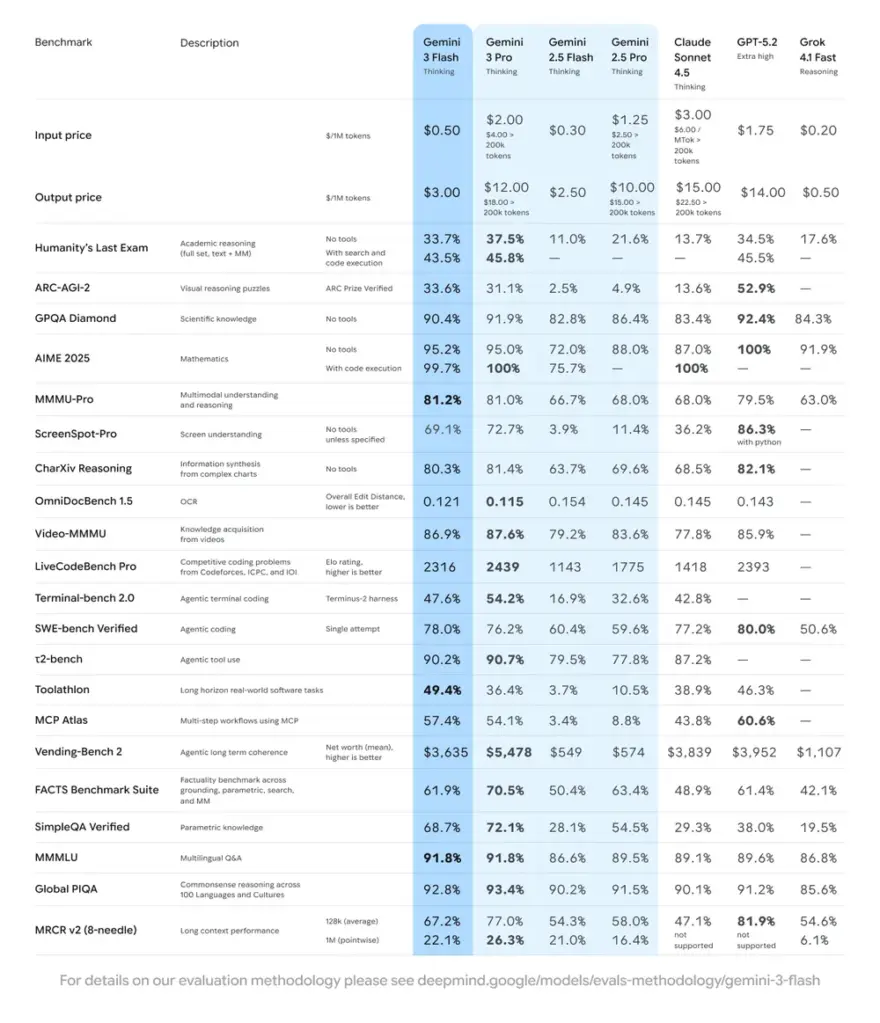
Note: Gemini 3 Flash achieves 78.0% on SWE-bench Verified, outperforming the previous Gemini 3 Pro (76.2%) while being 3x faster and 6x cheaper ($0.50/1M input).
The Implementation: Dynamic Reasoning with Vertex AI
The following Python implementation demonstrates how to integrate Gemini 3 Flash with dynamic reasoning levels. This script sets up a “Triage Agent” that adjusts its thinking depth based on query complexity.
Prerequisites:
google-cloud-aiplatform(v1.65.0+)- Valid GCP Project with Vertex AI enabled.
import vertexai
from vertexai.generative_models import GenerativeModel, SafetySetting
from google.api_core.exceptions import ResourceExhausted
# Configuration
PROJECT_ID = "your-gcp-project-id"
LOCATION = "us-central1"
MODEL_ID = "gemini-3-flash-preview"
vertexai.init(project=PROJECT_ID, location=LOCATION)
def generate_with_reasoning(prompt: str, complexity: str = "LOW"):
"""
Generates a response using Gemini 3 Flash with dynamic thinking levels.
Args:
prompt: The user input.
complexity: 'MINIMAL', 'LOW', 'MEDIUM', or 'HIGH'.
"""
# Map string complexity to Thinking Level constants
# Note: Ensure your SDK version supports the 'thinking_config' parameter
thinking_config = {"thinking_level": complexity}
model = GenerativeModel(
model_name=MODEL_ID,
system_instruction=[
"You are a senior backend engineer.",
"Solve the user's problem with production-ready Python code.",
"Minimize dependencies."
]
)
try:
response = model.generate_content(
prompt,
generation_config={
"max_output_tokens": 8192,
"temperature": 0.7,
# The core breakthrough: Dynamic Thinking Config
"thinking_config": thinking_config
}
)
# In Gemini 3, 'thoughts' might be accessible in metadata if enabled,
# but the standard response text contains the final answer.
return response.text
except ResourceExhausted:
print("Quota exceeded. Implement exponential backoff.")
return None
except Exception as e:
print(f"Error during generation: {e}")
return None
# --- Usage Examples ---
# Scenario 1: Simple Extraction (Fast, Cheap)
simple_task = "Extract the JSON object from this log string: [LOG 12:00] {user_id: 5}..."
print(f"Simple Output:\n{generate_with_reasoning(simple_task, complexity='MINIMAL')}")
# Scenario 2: Complex Architecture (Deep, Reliable)
complex_task = """
Design a scalable rate-limiting system using Redis and Lua scripts.
Handle race conditions for distributed counters.
Provide the Lua script.
"""
print(f"\nComplex Output:\n{generate_with_reasoning(complex_task, complexity='HIGH')}")
Implementation Steps
- Update SDKs: Run
pip install --upgrade google-cloud-aiplatformto ensure access to thethinking_configparameter. - Verify Model Access: Check the Google Cloud Model Garden to ensure
gemini-3-flash-previewis enabled for your region. - Refactor Logic: Identify high-latency calls in your current application that use
gpt-4orgemini-1.5-pro. - Implement Triage: Replace them with
gemini-3-flash-preview. Start withcomplexity="LOW"and scale up toHIGHonly when validation fails or for known complex routes. - Monitor Costs: Watch your billing. Although Flash is cheaper ($0.50/1M input), setting
complexity="HIGH"generates significant hidden “thought” tokens that count toward output limits (though currently billed at a lower rate or bundled, check the latest pricing page).
Gemini 3 Flash renders the “Pro” tier obsolete for 90% of engineering workflows. By intelligently toggling the thinking_level, you can achieve GPT-5.2 level reasoning on complex coding tasks (SWE-bench 78%) at a fraction of the latency and cost.
Key Takeaway: Stop defaulting to the largest model. Default to Flash + High Reasoning, and optimize down from there.