告别 PPO 与 DPO:深度解析 GRPO、DAPO 与 GSPO —— 下一代 LLM 对齐技术栈
在 2023-2024 年,RLHF(Reinforcement Learning from Human Feedbac…
Empowering Developers with AI Prompts and Tools

在 2023-2024 年,RLHF(Reinforcement Learning from Human Feedbac…
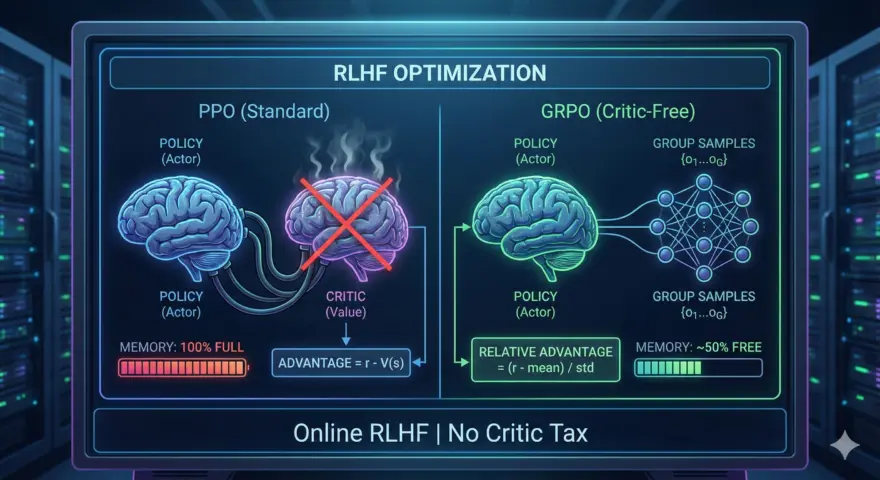
瓶颈:PPO 的显存重负与 DPO 的局限 多年来,Proximal Policy Optimization (PPO)…

核心瓶颈:“智能”与“速度”的死锁 在过去两年中,构建生产级 AI Agent(智能体)一直面临一个痛苦的权衡。开发者…

瓶颈所在:不再仅仅是模型的问题 进入 2026 年,生成式 AI 面临的挑战不再是寻找可用的模型,而是如何高效地进行推理…

围绕大型语言模型(LLM)的工程学科,已从早期的零散实验脚本拼凑,演变为一套严谨、分层的软件技术栈。时至 2025 年末…

推理预算急速消耗——你正在烧钱。无论是“2加2等于几?”这样的简单查询,还是复杂的 RAG(检索增强生成)合成任务,每一…
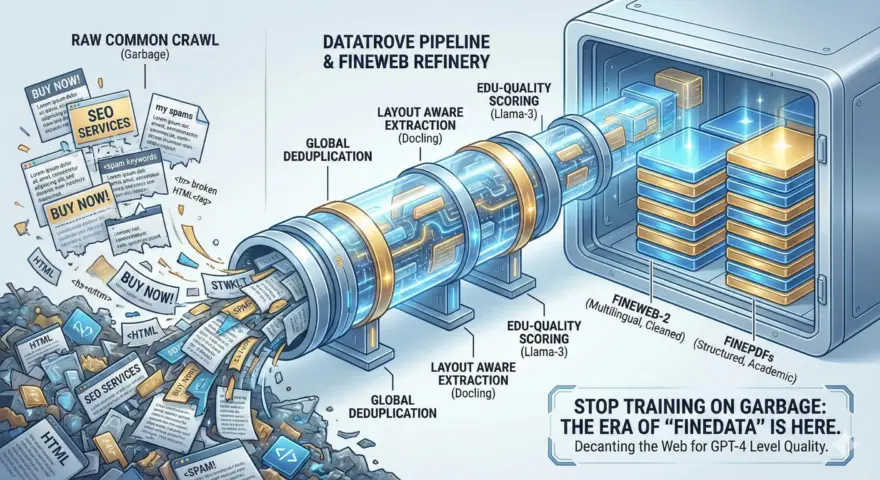
模型的智能上限取决于训练阶段的 Token 质量。如果到了 2025 年底,你还在直接使用原始的 Common Craw…

U-Net 的统治时代已成过往。本文将带你通过代码与架构图,一窥驱动 2025 年生成式 AI 革命的核心技术。 多年来…

长上下文 AI 的速度迎来了质的飞跃,而成本却大幅下降。 DeepSeek-V3.2(2025年12月1日发布)的问世,…
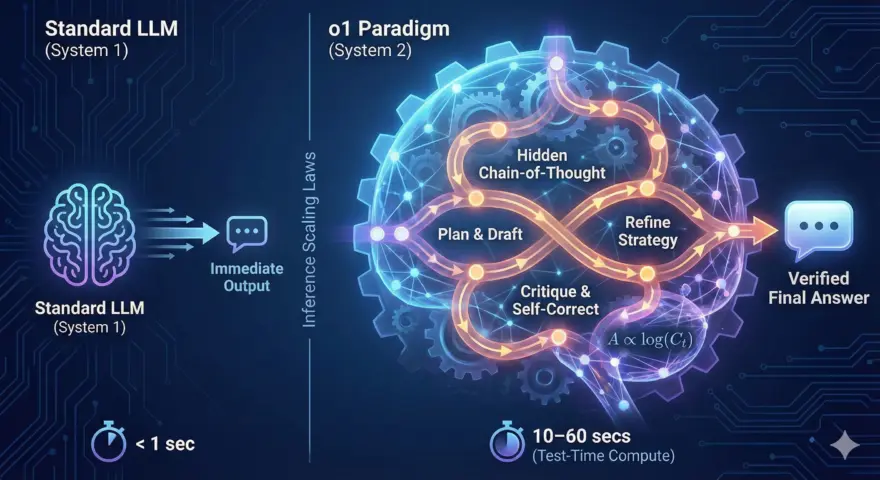
如果你用过 OpenAI 的 o 系列模型(如 o1, o3, o4),你肯定注意到了一个令人不安的现象:停顿 (The…