PPO와 DPO를 넘어: GRPO, DAPO, GSPO – 차세대 LLM 정렬(Alignment) 기술 스택 심층 분석
2023-2024년 RLHF(Reinforcement Learning from Human Feedback)의…
Empowering Developers with AI Prompts and Tools

2023-2024년 RLHF(Reinforcement Learning from Human Feedback)의…
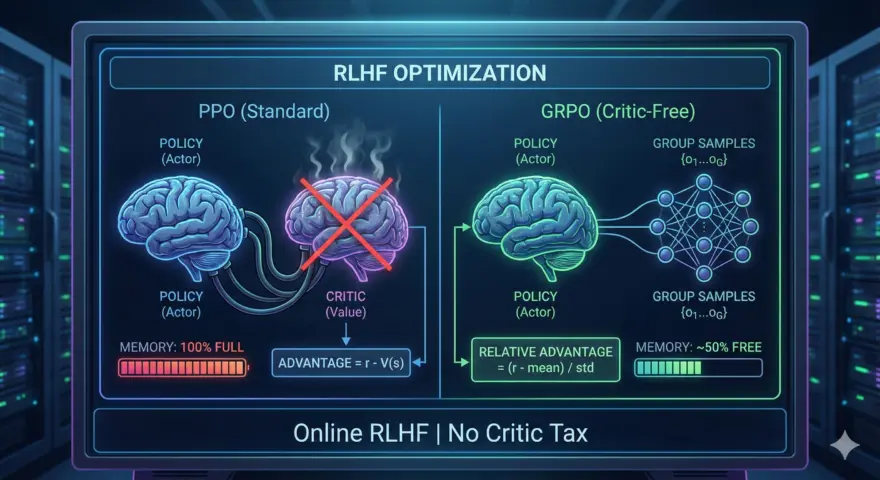
병목(Bottleneck): PPO의 메모리 비용과 DPO의 한계 수년 동안 Proximal Policy O…

병목 현상: ‘성능’과 ‘속도’ 사이의 교착 상태 지난 2년 동안…

병목 현상: 이제 더 이상 모델만의 문제가 아닙니다 2026년 현재, 생성형 AI의 과제는 ‘작동…

거대언어모델(LLM)을 다루는 엔지니어링 분야는 실험적인 스크립트의 산발적인 모음에서 벗어나, 이제는 엄격하…

기술적 병목 현상: 추론(Inference) 예산이 빠르게 소진되고 있습니다. “2+2는 무엇인가…
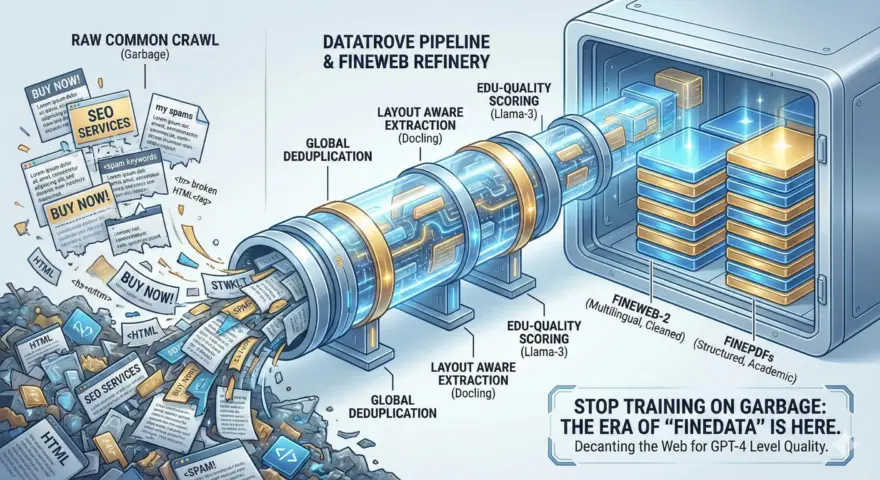
모델의 지능은 모델이 섭취하는 토큰의 질에 달려 있습니다. 2025년 말인 지금도 여전히 정제되지 않은 Co…

U-Net의 독주는 끝났습니다. 2025년 생성형 AI 혁명을 이끄는 새로운 아키텍처를 소개합니다. 수년 동…

긴 문맥(Long-context) AI가 더 빨라지고, 훨씬 저렴해졌습니다. 2025년 12월 1일 공개된 …
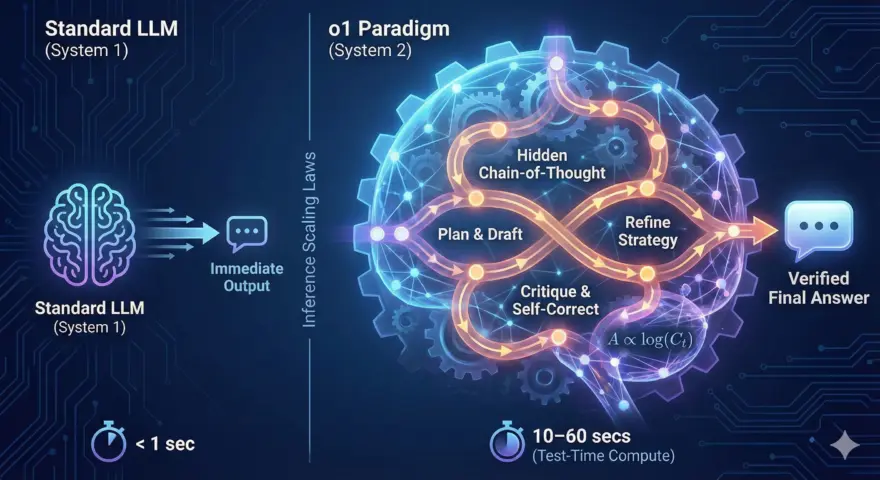
OpenAI의 o-시리즈 모델(o1, o3, o4 등)을 사용해 보셨다면, 무언가 당혹스러운 점을 발견하셨을…