Context Compression vs. Retrieval: Practical AI Prompts for Choosing the Right Memory Strategy
Most AI workflows do not fail because the model runs out of …
Empowering Developers with AI Prompts and Tools

Most AI workflows do not fail because the model runs out of …
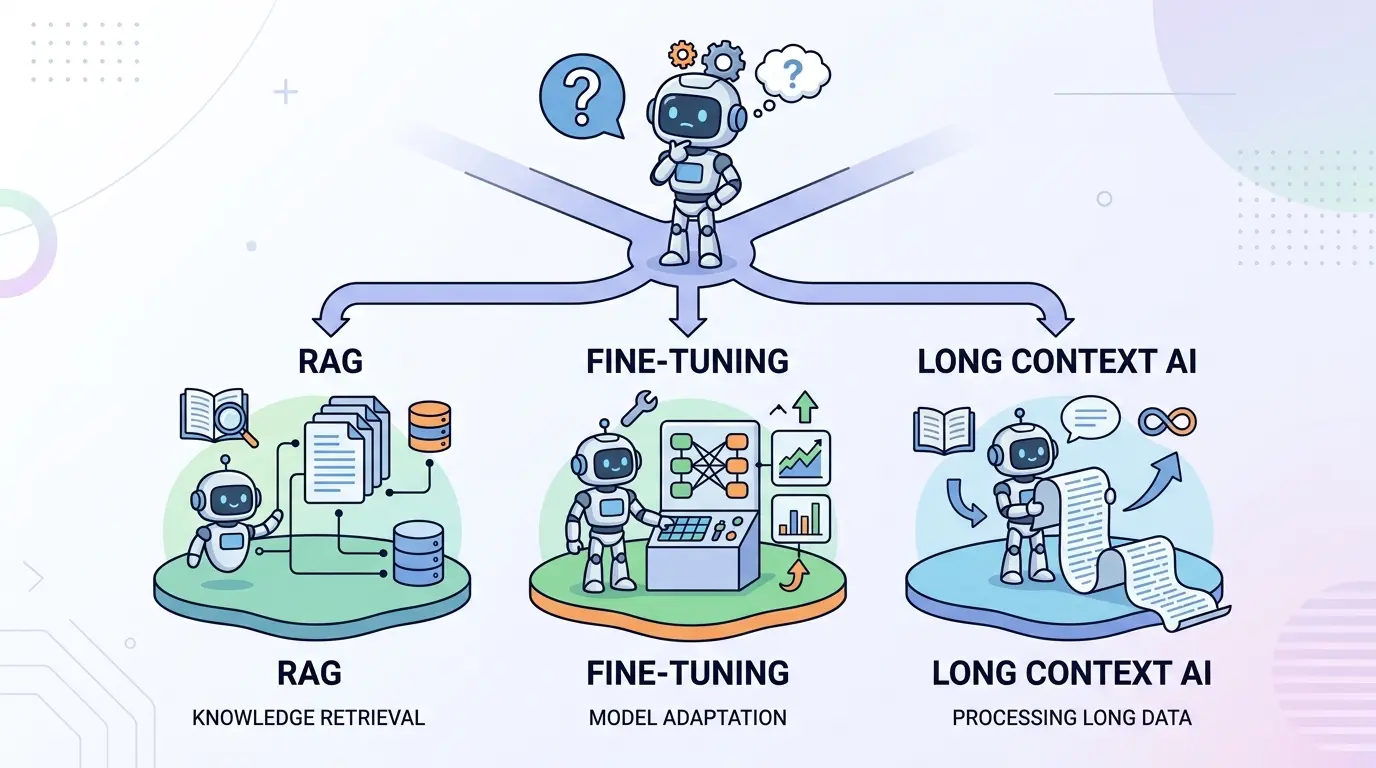
Most AI teams do not fail because they picked a weak model. …

Most teams do not lose control of AI spend because one model…
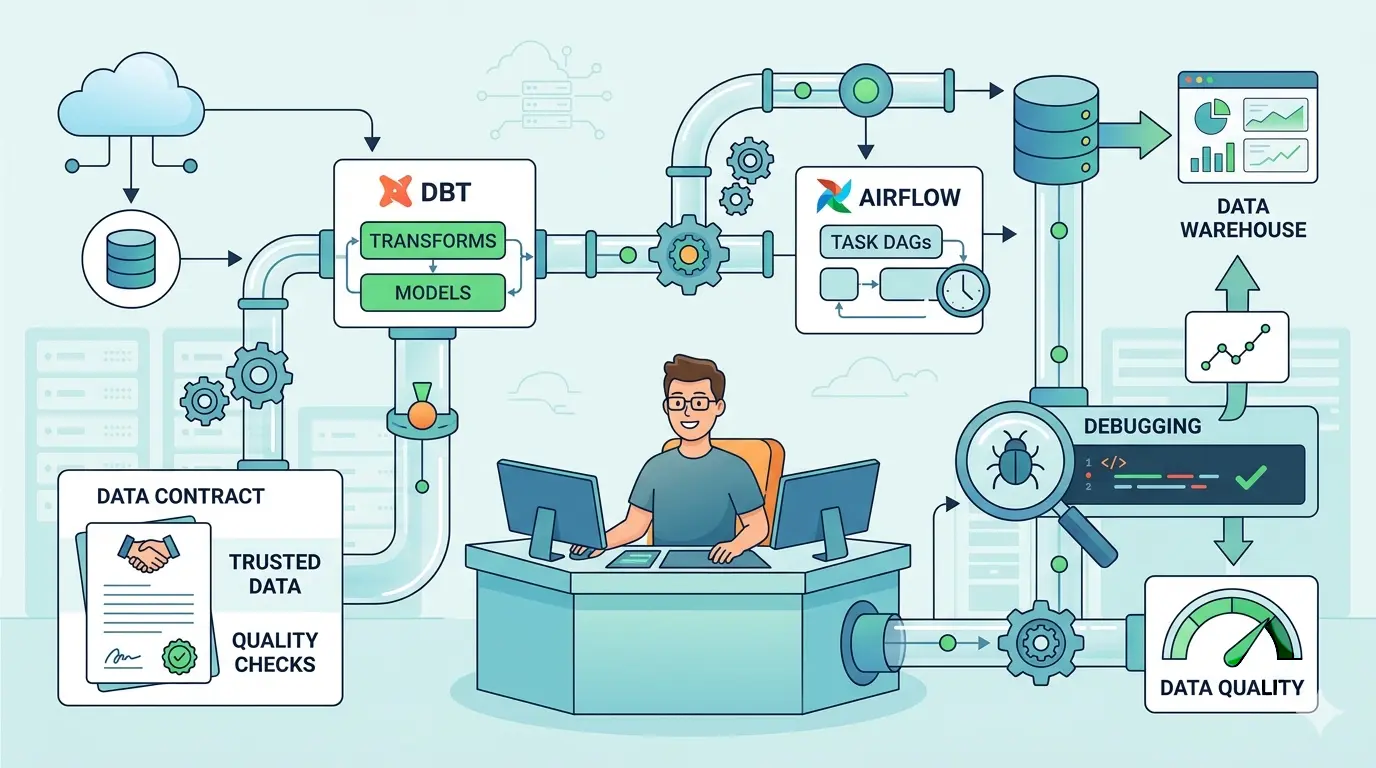
Data engineers rarely get blocked by SQL syntax alone. The r…

An AI feature can look promising in a demo and still collaps…
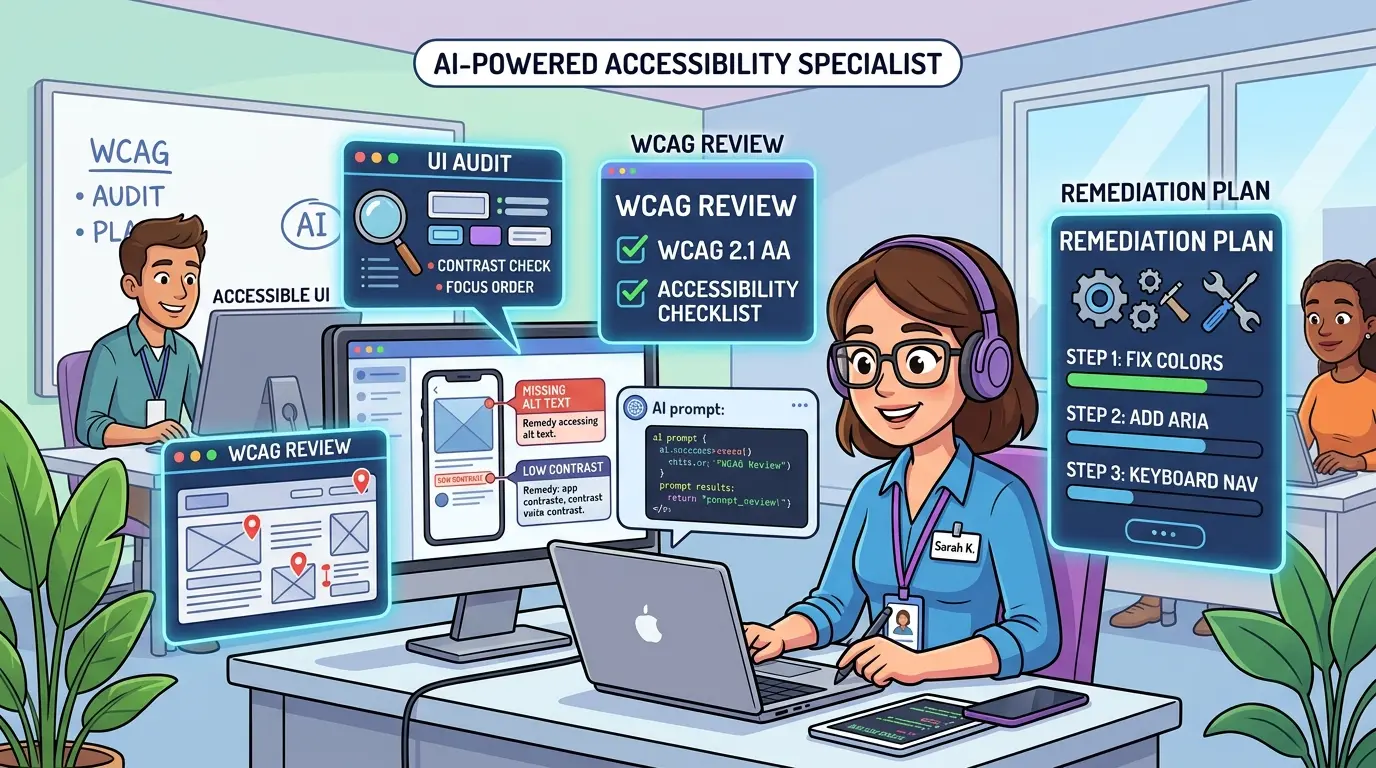
Accessibility specialists rarely get slowed down by knowing …
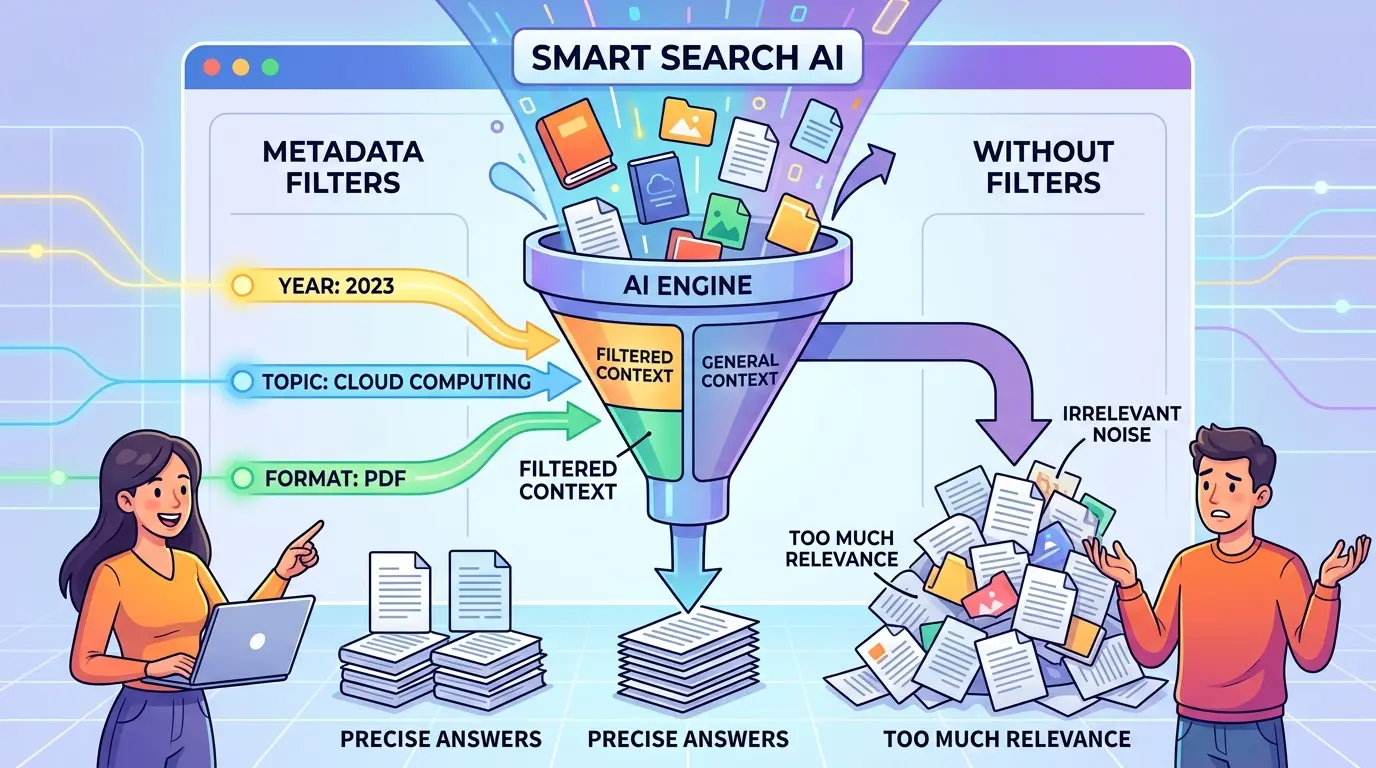
The failure mode is usually quiet. A RAG system returns docu…
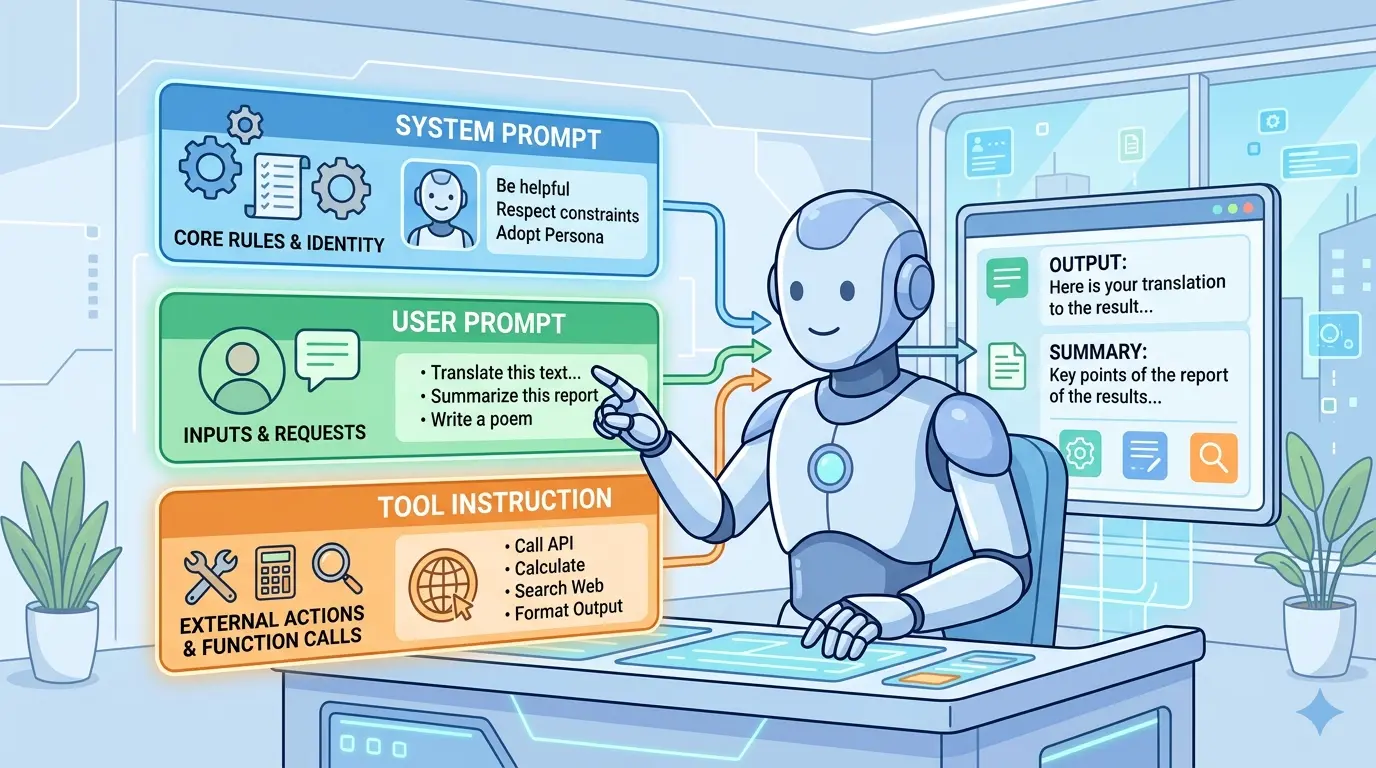
Most prompt failures are not model failures. They happen bec…
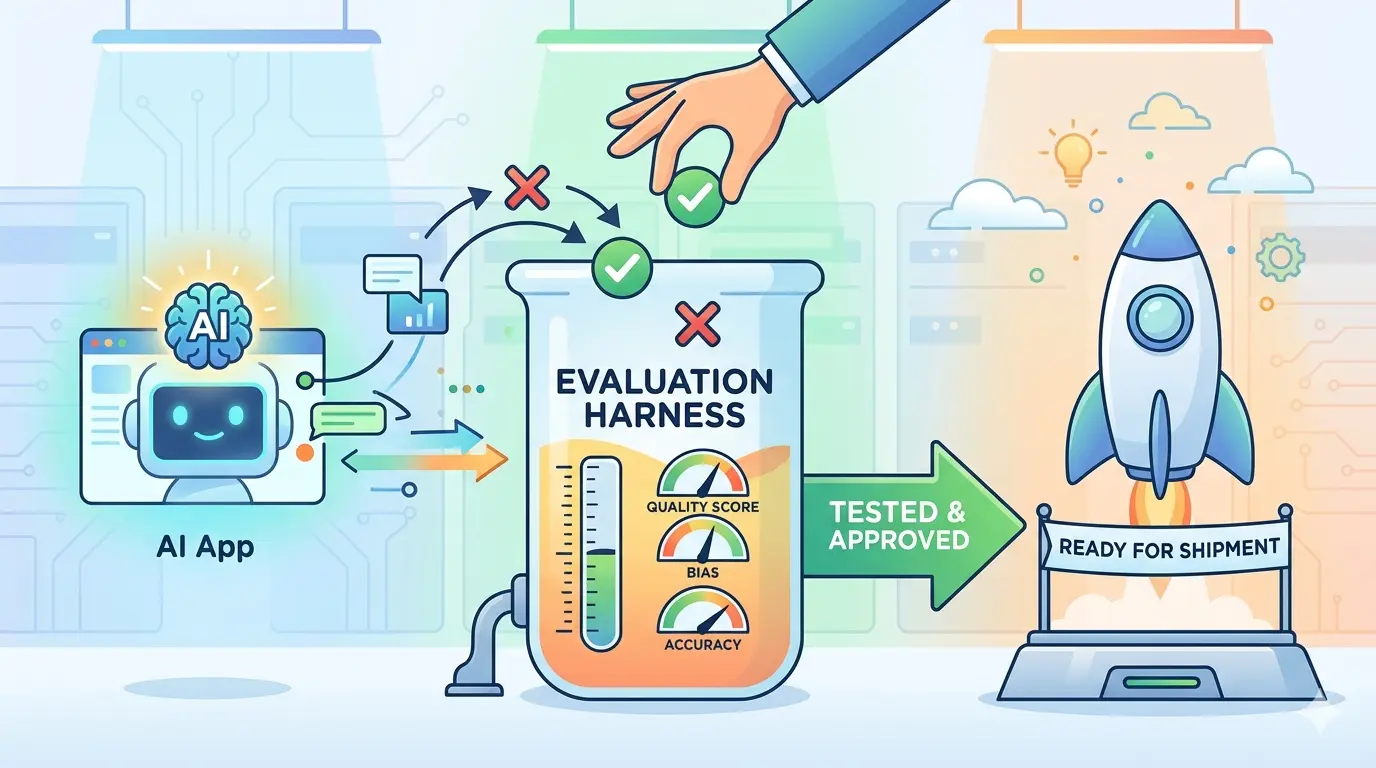
Teams hit the same bottleneck over and over: an AI feature l…

The integration of browser automation with Large Language Mo…